VLOGGER AI: 写真から本物のようなアバターを作成し、声を使ってそれをコントロールしましょう
Google の研究者は、AI テクノロジーをよりスマートにするために日々取り組んでいます。彼らが取り組んでいる最新の研究プロジェクトの 1 つは VLOGGER です。
VLOGGER について説明すると、
GitHubのブログ投稿によると、このアプローチにより、望ましい長さの高品質ビデオの生成が可能になります。すべての人にトレーニングを施す必要がなく、顔検出のトリミングに依存しません。完全なイメージを生成し、幅広いスペクトルを考慮に入れることができます。これは、コミュニケーションを行う人間を統合するために重要です。
現時点では、VLOGGER はまだ開発中のため使用できませんが、市場に投入されれば、Skype、Teams、または Slack でのビデオ会議でコミュニケーションを図るための優れた方法となる可能性があります。
Google はこのプロジェクトに非常に自信を持っており、さまざまなベンチマークを通じてテストしました。これは次のとおりです。
VLOGGERはどのように機能しますか?
VLOGGER は 2 段階のパイプラインとして機能するフレームワークで、テキストを画像、ビデオ、さらには 3D モデルに変換するだけでなく、制御メカニズムも追加する確率的拡散アーキテクチャに基づいて動作します。
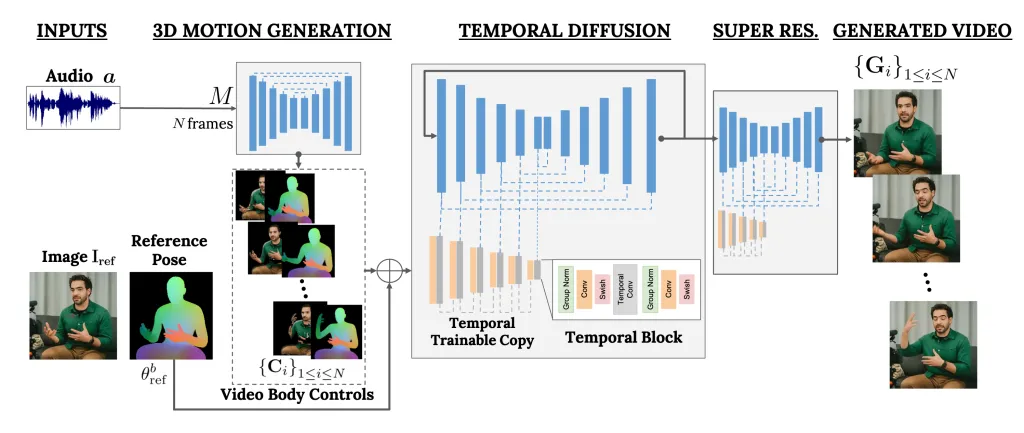
最初のステップは、音声波形を入力として取得し、視線や顔の表情などの中間的な身体動作制御を生成することです。次に、2 番目のネットワークは、時間的な画像間変換モデルを使用してこれらの動きを識別し、人の参照画像を使用してビデオのフレームを生成します。
VLOGGER のもう 1 つの重要な機能は、既存のビデオを編集できることです。ビデオを撮影し、ビデオ内の人物の表情を変えることができます。
さらに、VLOGGER はビデオ翻訳にも役立ちます。特定の言語で既存のビデオを取得し、唇と顔の領域を編集して、新しい音声や別の言語と一致させることができます。
VLOGGER は製品ではなく研究プロジェクトであり、完全ではないため、信頼できません。はい、現実的な動きを作成できますが、実際の人間の動きには一致しない可能性があります。その拡散モデルを考慮すると、異常な動作を示す可能性があります。
そのチームはまた、大きな動きや多様な環境には慣れておらず、短いビデオでしか機能しないとも述べています。
役に立つと思いますか?以下のコメントセクションで読者と意見を共有してください
3 つの異なるベンチマークで VLOGGER を評価し、提案されたモデルが画質、同一性の保持、および時間的一貫性の点で他の最先端の方法を上回ることを示します。私たちは、以前のデータセット (2,200 時間と 800,000 のアイデンティティ、および 120 時間と 4,000 のアイデンティティのテスト セット) よりも 1 桁大きい、新しく多様なデータセット MENTOR を収集し、これに基づいて主要な技術的貢献をトレーニングおよびアブレーションします。複数の多様性メトリクスに関する VLOGGER のパフォーマンスを報告し、アーキテクチャの選択が公平で不偏なモデルを大規模にトレーニングすることに有益であることを示しています。
最近の生成拡散モデルの成功に基づいて、人物の 1 つの入力画像からテキストおよびオーディオ主導の会話人間ビデオを生成する方法。
私たちの方法は、1) 人間から 3D モーションへの確率的拡散モデル、および 2) 時間的および空間的制御の両方でテキストから画像へのモデルを強化する新しい拡散ベースのアーキテクチャで構成されます。


コメントを残す