Sztuczna inteligencja dostaje się do Twojej przeglądarki i jest szybsza niż kiedykolwiek
Zastanawialiśmy się, kiedy w naszych przeglądarkach wykorzystają pełną moc AI i najwyraźniej nadszedł ten czas.
Mówimy o nowej funkcji o nazwie ONNX Runtime Web, która wykorzystuje akcelerator WebGPU, który pozwala na wbudowanie modeli AI bezpośrednio w przeglądarkę i przyspieszenie ich. Dużo szybciej!
Co to jest sieć uruchomieniowa ONNX?
Aby to wyjaśnić, musisz wiedzieć, że WebGPU jest silnikiem, podobnie jak WebGL, ale o wiele potężniejszym, zdolnym poradzić sobie z większymi obciążeniami obliczeniowymi. Zasadniczo polega to na wykorzystaniu mocy procesora graficznego do wykonywania równoległych zadań obliczeniowych potrzebnych w procesach AI.
Teraz, przechodząc do ONNX Runtime Web, jest to biblioteka JavaScript, która umożliwia twórcom stron internetowych osadzanie LLM bezpośrednio w przeglądarkach internetowych i korzystanie z akceleracji sprzętowej GPU.
Zwykle dużych LLM nie można tak łatwo wdrożyć w przeglądarkach, ponieważ wymagają dużo pamięci i mocy obliczeniowej.
Innowacją ONNX Runtime Web jest umożliwienie obsługi backendu WebGPU, nad którym obecnie pracują Microsoft i Intel.
Jak szybka jest sieć uruchomieniowa ONNX?
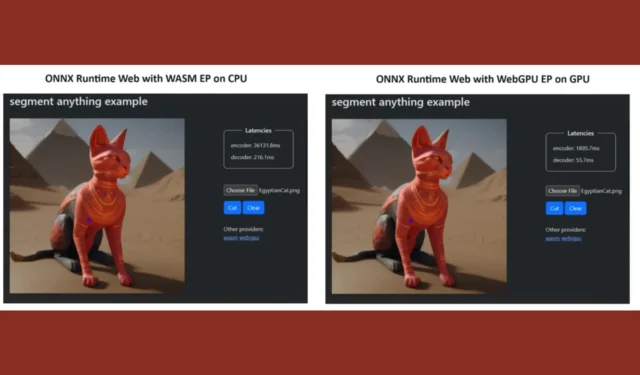
Aby udowodnić swoją rację, zespół ONNX Runtime stworzył demo przy użyciu modelu Segment Everything , a wyniki były wręcz zdumiewające.
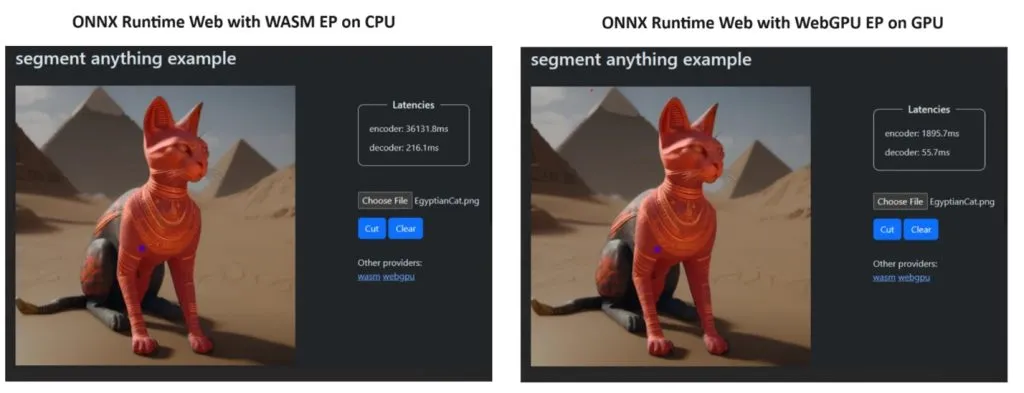
Włączyli WASM EP i WebGPU EP oraz wykorzystali komputer NVIDIA GeForce RTX 3060 i Intel Core i9. Następnie porównali koder wykorzystujący procesor i nowy WebGPU, który okazał się znacznie szybszy, co widać na powyższym zrzucie ekranu.
Dobra wiadomość jest taka, że WebGPU jest już wbudowane w Chrome 113 i Edge 113 dla Windows, macOS i ChromeOS oraz Chrome 121 na Androida. Oznacza to, że możesz także grać w ONNX Runtime Web w tych przeglądarkach.
Twórcy wyjaśnili, jak wypróbować ONNX Runtime Web na swojej stronie projektu:
Skoro już mamy już wszystko gotowe, zacznijmy wdrażać potężne narzędzia LLM w przeglądarkach!
Co sądzisz o nowym środowisku wykonawczym ONNX? Porozmawiajmy o tym rozwoju w sekcji komentarzy poniżej.
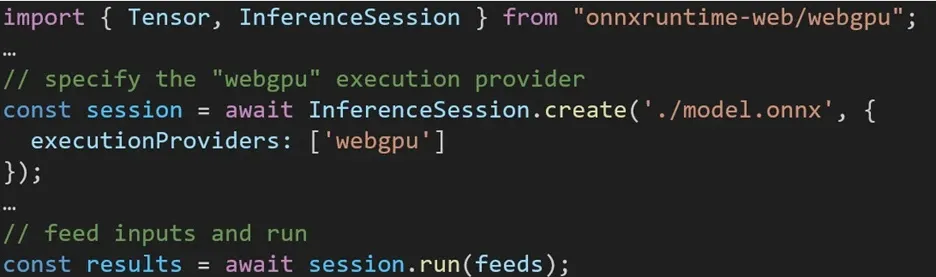
Korzystanie z różnych backendów w ONNX Runtime Web jest proste. Po prostu zaimportuj odpowiedni pakiet i utwórz sesję wnioskowania sieciowego ONNX Runtime z wymaganym backendem za pomocą ustawienia dostawcy wykonania. Naszym celem jest uproszczenie procesu dla programistów, umożliwiając im wykorzystanie różnych akceleracji sprzętowych przy minimalnym wysiłku.
Poniższy fragment kodu pokazuje, jak wywołać interfejs API sieci Web ONNX Runtime w celu wywnioskowania modelu za pomocą WebGPU. Dostępna jest dodatkowa dokumentacja i przykłady środowiska uruchomieniowego ONNX w Internecie, umożliwiające głębsze zgłębienie tematu.


Dodaj komentarz