VLOGGER AI: Maak nu een levensechte avatar van een foto en gebruik je stem om deze te besturen
Onderzoekers bij Google werken er elke dag aan om de AI-technologie slimmer te maken. Een van de nieuwste onderzoeksprojecten waar ze aan werken is VLOGGER.
VLOGGER wordt uitgelegd als
Volgens de blogpost op GitHub maakt deze aanpak het genereren van video’s van hoge kwaliteit met de gewenste lengte mogelijk. Zonder de noodzaak van training voor ieder persoon, is het niet afhankelijk van het bijsnijden van gezichtsdetectie; het kan het volledige beeld genereren en rekening houden met een breed spectrum, wat belangrijk is voor het synthetiseren van mensen die communiceren.
Momenteel is VLOGGER nog niet beschikbaar voor gebruik omdat het nog in ontwikkeling is, maar wanneer het op de markt komt, kan het een geweldige manier zijn om te communiceren tijdens een videoconferentie op Skype, Teams of Slack.
Google heeft veel vertrouwen in het project en heeft het via verschillende benchmarks getest; hier is wat er staat:
Hoe werkt VLOGGER?
VLOGGER is een raamwerk dat fungeert als een tweetrapspijplijn en werkt aan stochastische diffusiearchitectuur die tekst naar beeld, video en zelfs 3D-modellen stuurt, maar ook een controlemechanisme toevoegt.
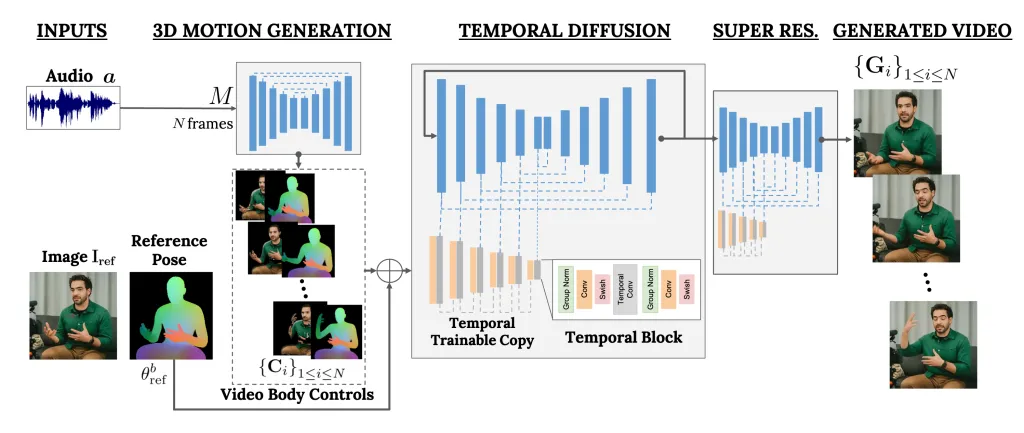
De eerste stap is het nemen van een audiogolfvorm als input om tussenliggende lichaamsbewegingen zoals blikken en gezichtsuitdrukkingen te genereren. Vervolgens gebruikt het tweede netwerk een temporeel beeld-naar-beeld-vertaalmodel om deze bewegingen te identificeren en een referentiebeeld van een persoon om frames voor de video te genereren.
Een ander belangrijk kenmerk van VLOGGER is de mogelijkheid om bestaande video’s te bewerken. Er kan een video voor nodig zijn en de uitdrukking van de persoon in de video veranderen.
Bovendien kan de VLOGGER ook helpen bij videovertaling; het kan een bestaande video in een specifieke taal nemen en het lippen- en gezichtsgebied bewerken om het consistent te maken met nieuwe audio of andere talen.
Omdat VLOGGER geen product is, maar een onderzoeksproject en niet compleet is, kan er niet op worden vertrouwd. Ja, het kan realistische bewegingen creëren, maar het kan mogelijk niet overeenkomen met hoe iemand werkelijk beweegt. Gezien het verspreidingsmodel zou het ongewoon gedrag kunnen vertonen.
Het team zei ook dat het niet thuis is in grote bewegingen of diverse omgevingen en alleen voor korte video’s kan werken.
Denkt u dat het nuttig voor u kan zijn? Deel uw mening met onze lezers in de opmerkingen hieronder
We evalueren VLOGGER op drie verschillende benchmarks en laten zien dat het voorgestelde model andere state-of-the-art methoden overtreft op het gebied van beeldkwaliteit, identiteitsbehoud en temporele consistentie. We verzamelen een nieuwe en diverse dataset MENTOR die een orde van grootte groter is dan de vorige (2.200 uur en 800.000 identiteiten, en een testset van 120 uur en 4.000 identiteiten) waarop we onze belangrijkste technische bijdragen trainen en ablateren. We rapporteren de prestaties van VLOGGER met betrekking tot meerdere diversiteitsstatistieken, waaruit blijkt dat onze architecturale keuzes ten goede komen aan het trainen van een eerlijk en onbevooroordeeld model op schaal.
Een methode voor tekst- en audiogestuurde pratende menselijke videogeneratie op basis van een enkel invoerbeeld van een persoon, die voortbouwt op het succes van recente generatieve diffusiemodellen.
Onze methode bestaat uit 1) een stochastisch diffusiemodel van mens naar 3D-beweging, en 2) een nieuwe op diffusie gebaseerde architectuur die tekst-naar-beeldmodellen uitbreidt met zowel temporele als ruimtelijke controles.


Geef een reactie