AI がブラウザに取り込まれ、これまでよりも高速になります
私たちは、いつブラウザ内で AI の全能力を活用するのかと疑問に思っていましたが、どうやらその時が来たようです。
ONNX Runtime Web と呼ばれる新機能について話しています。これは WebGPU アクセラレータを使用し、AI モデルをブラウザに直接組み込んで高速化できるようにします。かなり速くなりました!
ONNX ランタイム Web とは何ですか?
これを説明するには、WebGPU は WebGL と同様のエンジンですが、より強力で、より大きな計算ワークロードを処理できることを知っておく必要があります。基本的には GPU の能力を利用して、AI プロセスに必要な並列計算タスクを実行します。
ONNX ランタイム Web について説明します。ONNX ランタイム Web は、Web 開発者が LLM を Web ブラウザに直接埋め込み、GPU ハードウェア アクセラレーションの恩恵を受けることを可能にする JavaScript ライブラリです。
通常、大規模な LLM は大量のメモリと計算能力を必要とするため、ブラウザに展開するのはそれほど簡単ではありません。
ONNX Runtime Web の革新的な点は、Microsoft と Intel が現在開発中の WebGPU バックエンドを可能にすることです。
ONNX ランタイム Web の速度はどれくらいですか?
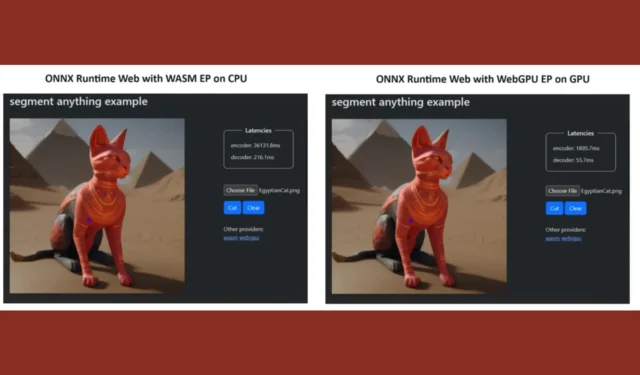
自分たちの主張を証明するために、ONNX ランタイム チームはSegment Anything モデルを使用してデモを作成しました。その結果は驚くべきものでした。
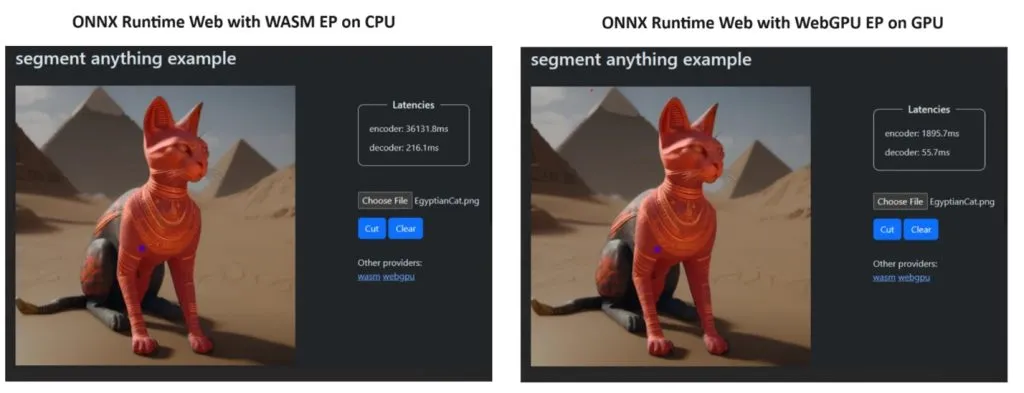
WASM EP と WebGPU EP を組み込み、NVIDIA GeForce RTX 3060 と Intel Core i9 PC を使用しました。次に、CPU と新しい WebGPU を使用したエンコーダを比較したところ、上のスクリーンショットに示すように、後者の方がはるかに高速であることが判明しました。
良いニュースとして、WebGPU は Windows、macOS、ChromeOS の Chrome 113 と Edge 113、Android の Chrome 121 にすでに組み込まれています。つまり、これらのブラウザでも ONNX ランタイム Web を操作できるということです。
開発者は、プロジェクト ページで ONNX Runtime Web を試す方法を説明しました。
さて、準備が整ったので、ブラウザへの強力な LLM のデプロイを開始しましょう。
新しい ONNX ランタイム Web についてどう思いますか?以下のコメントセクションでこの開発について話し合いましょう。
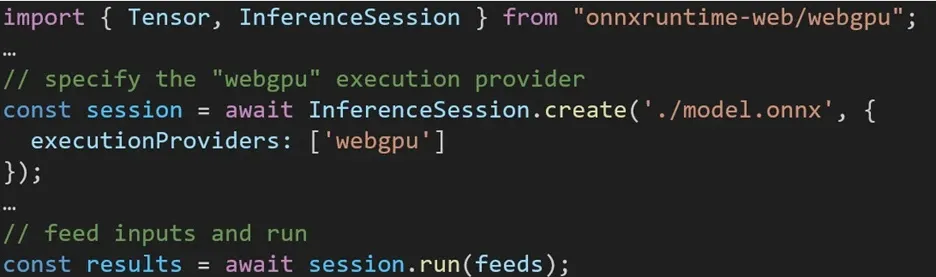
ONNX ランタイム Web でさまざまなバックエンドを利用するエクスペリエンスは簡単です。関連するパッケージをインポートし、実行プロバイダー設定を通じて必要なバックエンドを使用して ONNX ランタイム Web 推論セッションを作成するだけです。私たちは開発者のプロセスを簡素化し、最小限の労力でさまざまなハードウェア アクセラレーションを活用できるようにすることを目指しています。
次のコード スニペットは、ONNX ランタイム Web API を呼び出して WebGPU でモデルを推論する方法を示しています。さらに詳しく調べるために、追加のONNX ランタイム Web ドキュメントと例にアクセスできます。


コメントを残す