
VLOGGER AI:現在從照片中創建一個栩栩如生的頭像並使用你的聲音來控制它
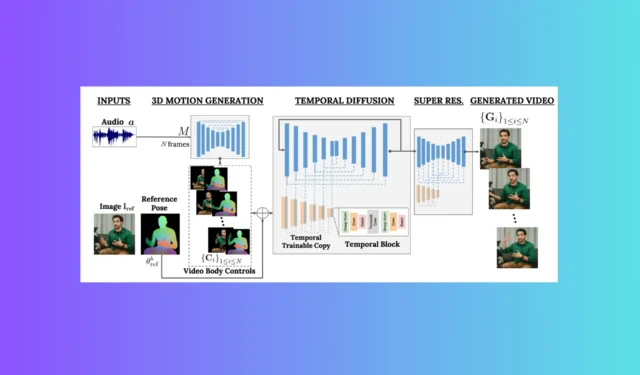
谷歌的研究人員每天都在致力於使其人工智慧技術變得更加智慧。他們正在進行的最新研究項目之一是 VLOGGER。
VLOGGER解釋為
根據GitHub上的部落格文章,這種方法可以產生所需長度的高品質影片。無需對每個人進行訓練,不依賴人臉偵測裁切;它可以產生完整的圖像並考慮到廣泛的範圍,這對於合成交流的人類非常重要。
截至目前,VLOGGER 尚未投入使用,因為它仍在開發中,但當它上市時,它可能成為在 Skype、Teams 或 Slack 上進行視訊會議溝通的好方法。
谷歌對該專案非常有信心,並通過各種基準測試對其進行了測試;它是這樣說的:
VLOGGER如何運作?
VLOGGER 是一個充當兩級管道的框架,採用隨機擴散架構,支援文字到圖像、視訊甚至 3D 模型,但也添加了控制機制。
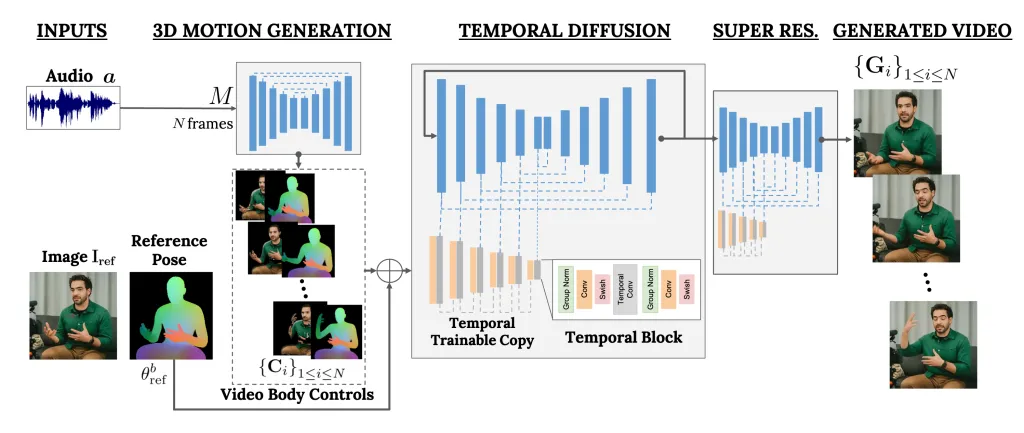
第一步是將音訊波形作為輸入來產生中間身體運動控制,例如凝視和臉部表情。接下來,第二個網路使用時間圖像到圖像轉換模型來識別這些動作,並使用人的參考圖像來產生視訊幀。
VLOGGER 的另一個重要功能是編輯現有影片的能力。它可以拍攝影片並改變影片中人的表情。
此外,VLOGGER還可以幫助進行視訊翻譯;它可以拍攝特定語言的現有影片並編輯嘴唇和臉部區域,使其與新音訊或不同語言保持一致。
由於VLOGGER不是一個產品,而是一個研究項目,而且還不完整,所以不能依賴。是的,它可以創造出逼真的動作,但它可能無法匹配人的真實動作。鑑於其擴散模型,它可能會表現出不尋常的行為。
其團隊也提到,它不擅長大動作或多樣化環境,只能適用於短影片。
您認為這對您有幫助嗎?在下面的評論部分與我們的讀者分享您的意見
我們在三個不同的基準上評估 VLOGGER,並表明所提出的模型在影像品質、身分保存和時間一致性方面超越了其他最先進的方法。我們收集了一個新的、多樣化的資料集MENTOR,比以前的資料集大一個數量級(2,200 小時和800,000 個身份,以及一個120 小時和4,000 個身份的測試集),我們在此基礎上訓練和消除我們的主要技術貢獻。我們報告了 VLOGGER 在多個多元化指標方面的表現,顯示我們的架構選擇有利於大規模訓練公平且公正的模型。
一種從人的單一輸入圖像生成文字和音訊驅動的說話的人類視訊的方法,該方法建立在最近生成擴散模型的成功基礎上。
我們的方法包括 1) 隨機人體到 3D 運動擴散模型,以及 2) 一種新穎的基於擴散的架構,該架構通過時間和空間控制增強文本到圖像模型。


發佈留言