
Reddit 禁止 Bing 和其他搜尋引擎抓取其數據,但 Google 除外
要知道什麼
- Reddit 已更新其 robots.txt 文件,以防止 Bing 和其他搜尋引擎抓取該網站。
- Reddit 聲稱這次打擊行動是由於與搜尋引擎達成協議失敗以及公司不願就 Reddit 內容的使用做出可執行承諾的結果。
- 谷歌是唯一一個可以在搜尋結果中顯示 Reddit 最新內容的主要搜尋引擎,據稱是因為他們達成了 6000 萬美元的交易。
Reddit 正在加強阻止網路爬蟲使用其數據。由於打擊,目前沒有主要的搜尋引擎,無論是 Bing 還是 DuckDuckGo,都可以在其搜尋結果中提供最近的 Reddit 貼文和評論。除了谷歌之外沒有。
因此,如果您嘗試在搜尋引擎查詢中搜尋最近的 Reddit 結果,很遺憾您會找不到結果。比較 Bing 和 Google 上關於最近新聞討論的相同查詢的搜尋結果:
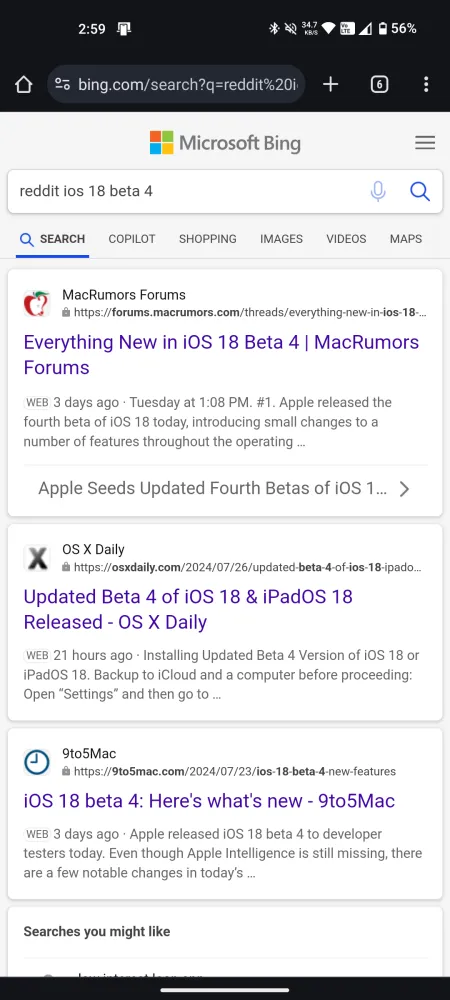
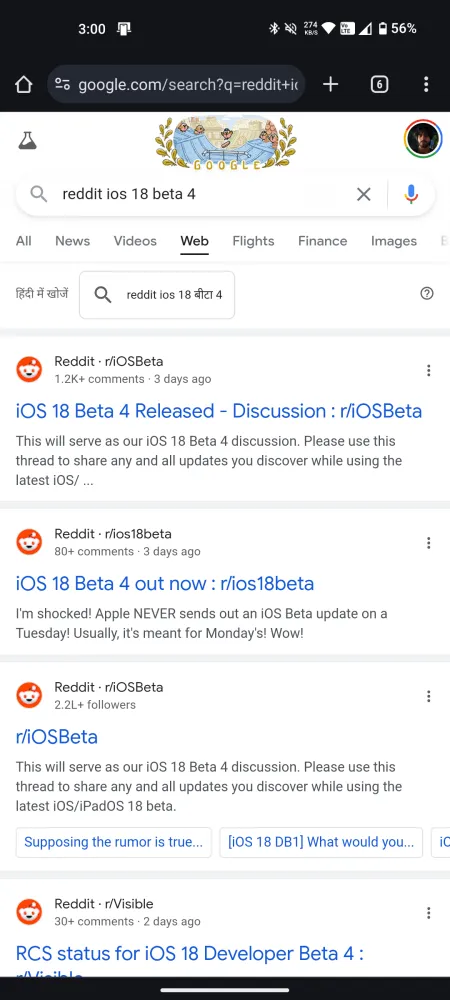
近年來,Reddit 對其資料的保護力度越來越大,這是可以理解的。作為一個受歡迎的社群論壇,人們聚集在一起討論和談論他們的興趣,這使得 Reddit 成為名副其實的人工智慧培訓金礦。但 Reddit 和人工智慧公司一樣明白,在人工智慧聊天機器人接管網路之際,該網站是多麼寶貴的資源。
為了保護自己的利益,Reddit 更新了robots.txt 文件,以防止網路爬蟲訪問該網站。在此之前,我們多次嘗試與不同搜尋引擎就 Reddit 內容的使用達成協議,但都以失敗告終。打擊搜尋引擎並阻止它們抓取資料是一個明確的信號,表明那些沒有達成協議的人不應該訪問 Reddit 內容。
目前,Google是唯一可以在搜尋結果中顯示 Reddit 貼文和評論的主要搜尋引擎。這也不是巧合。儘管Reddit 發言人在一份聲明中提到“這與我們最近與谷歌的合作關係完全無關”,但要回顧這筆6000 萬美元的交易並不容易,該交易允許谷歌利用Reddit 的數據訓練其人工智能模型。據稱,該交易還包括即時存取 Reddit 內容。
Reddit 上傳達的訊息非常明確:要麼付錢,要麼錯過。大多數公司,包括微軟,都已經承認了。微軟在聲明中表示:
「我們尊重 robots.txt 標準。 Bing 在 7 月 1 日實施更新的 robots.txt 檔案後停止了對 Reddit 的抓取,該檔案禁止對其網站的所有抓取。
使用非Google搜尋引擎的人處於明顯的劣勢,主要是因為Reddit自己的搜尋功能在尋找相關內容方面不如搜尋引擎那麼好用。目前,如果您想使用「site:reddit.com」技巧或透過在查詢中附加「Reddit」一詞來從 Reddit 取得最新結果,則必須先開啟 Google。


發佈留言