
Bluesky 承諾與其他平台不同,不會使用您的內容進行 AI 訓練
基本資訊:
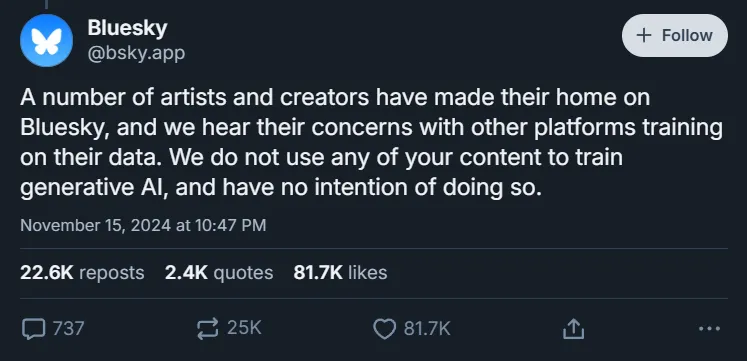
- Bluesky 明確承諾不會利用用戶生成的內容來訓練生成式 AI,這與 X 最近允許此類做法的政策不同。
- 該平台正在經歷令人印象深刻的成長,目前擁有超過 1700 萬用戶,並在過去一周迎來了超過 100 萬新註冊用戶。
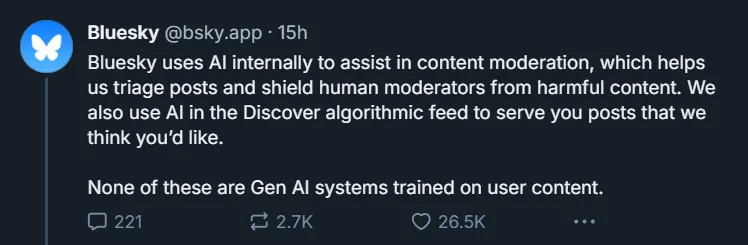
- 儘管 Bluesky 採用人工智慧技術進行內容審核並增強其 Discover feed,但它強調這些應用程式不涉及基於用戶資料訓練的生成式人工智慧。
為了區別於同行,Bluesky 正式表示不會使用用戶的貼文進行生成式 AI 模型訓練。此公告發布之際正值關鍵時刻,因為X(以前稱為 Twitter)最近修改了其服務條款,以允許利用用戶內容進行人工智慧訓練。
這個快速擴張的社群平台是在其用戶群顯著增加的情況下發布這項公告的, 24 小時內新註冊人數超過 100 萬,用戶總數超過1700 萬。這種湧入緊隨用戶與 X 的重大背離之後,特別是考慮到最近的政治轉變和政策修訂。
雖然 Bluesky 仍然致力於不使用用戶的貼文進行人工智慧培訓,但有一個重要的警告。根據The Verge報道,Bluesky 目前的技術框架並不能阻止主要 AI 實體潛在地抓取使用者內容。作為一個開放的公共網絡,Bluesky 的robots.txt 檔案允許Google和OpenAI等組織的爬蟲程式存取其資料。儘管如此,該公司保證正在努力製定措施,確保外部實體尊重用戶的同意。
Bluesky也指出,雖然它利用了人工智慧技術,但其應用僅限於特定目的。該平台採用人工智慧進行內容審核,有助於保護人類審核員免受有害內容的侵害,並增強了驅動其 Discover feed 的演算法。重要的是,該公司聲稱這些系統都沒有利用用戶生成的內容進行培訓。
對於那些尋求更全面見解的人來說,Bluesky 已在一個集中中心輕鬆存取其政策文檔,包括服務條款和社區指南。

對於在 Bluesky 找到了溫馨環境的藝術家和創作者來說,這個位置尤其重要。許多內容創作者對他們的工作被用於在競爭平台上訓練人工智慧表示擔憂,這凸顯了 Bluesky 承諾的重要性。
這項聲明的時機至關重要,恰逢 X 推出明確允許使用公共職位進行人工智慧培訓的新條款。用戶資料管理和人工智慧開發實踐的這種對比凸顯了不同社群媒體平台在處理用戶隱私和內容所有權問題上日益擴大的差距。


發佈留言