
要知道的最佳機器學習模型
如果您想利用人工智慧和機器學習的力量,您必須熟悉一些最好的機器學習模型。機器學習模型有數十種,因此在為專案選擇機器學習模型時可能會有點混亂。在這篇文章中,我們將討論一些您可以根據您的專案使用的最佳機器學習模型。
要知道的最佳機器學習模型
我們有以下項目、實例和場景的機器學習模型和演算法清單。
用於時間序列預測的機器學習模型
在數據分析中,時間序列預測依賴各種機器學習演算法,每種演算法都有自己的優勢。不過,我們將討論兩個最常用的。
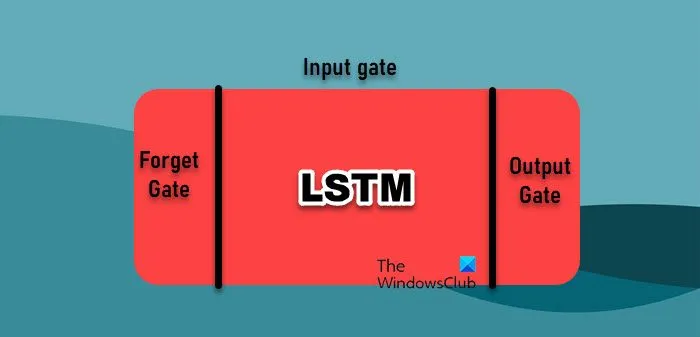
- 長短期記憶網路:長短期記憶 (LSTM) 網路是循環神經網路 (RNN) 的一種,在序列學習方面特別有效,因此非常適合時間序列資料。與傳統的 RNN 不同,傳統的 RNN 因梯度消失問題而難以應對長期依賴性,而 LSTM 可以長期保留資訊。這是透過其獨特的架構來實現的,其中包括管理資訊流的門,使他們能夠捕獲時間序列資料中的複雜模式。
- Randon Forest:隨機森林是一種整合學習方法(這裡有兩個或更多學習器)。在訓練過程中,它會建立多個決策樹,然後對它們的預測進行平均。儘管它最初不適用於時間序列,但可以透過包含滯後變數來調整它以進行預測。隨機森林可以處理許多特徵並且不太可能過度擬合,這使其成為複雜資料集的強大選擇。
您可以整合這兩個模型和其他一些模型,例如 VAR、ARIRA 和 Prophet 模型,以獲得最佳結果。
用於股票預測的機器學習模型

股票是隨機的,但同時,這種隨機性也有其模式。如果您的專案旨在進行股票預測,我們建議使用下面提到的一個或兩個模型。
- 決策樹:決策樹是一種有助於做出決策或預測的流程圖。它具有用於屬性決策或測試的節點、用於這些決策結果的分支以及用於最終結果或預測的葉節點。每個內部節點代表屬性的測試,每個分支代表測試的結果,每個葉節點代表一個類別標籤或連續值。
- 神經網路:神經網路是模仿人腦複雜功能的電腦模型。它們由互連的節點或神經元組成,處理資料並從資料中學習。這使得機器學習中的模式識別和決策等任務成為可能。如果你訓練得好,他們可以成為炒股大師。
然而,您需要記住,弄清楚股票模式可能非常棘手,因此不應過度依賴這些模型並結合其他模型,例如 Randon Forest 和 LSTM。
多類別分類的機器學習模型
現在,讓我們討論最常見的機器學習工作之一:多類別分類。在這裡,我們的工作是起草一個模型,在先前的數據的幫助下,可以查看一條資訊並將其分類。此模型分析訓練資料集以找到每個類別的獨特模式。然後,它使用這些模式來預測未來數據的類別。下面提到了兩種最常見的演算法和模型。
- SVM 擅長處理大量資訊並尋找模式,因此它們在許多不同領域都很有用。憑藉它提供的所有這些設施,它可用於監視數據並對數據進行分類。
- 它包括多項式樸素貝葉斯、伯努利樸素貝葉斯和高斯樸素貝葉斯。樸素貝葉斯分類器是一組基於貝葉斯定理的分類演算法。它們不僅僅是一個演算法,而是一系列演算法,都遵循相同的原則:每對被分類的特徵都是相互獨立的。
您也可以使用神經網路(上面提到的詳細資訊)來實現此功能。
回歸機器學習模型

迴歸用於預測連續值,這是最需要的功能之一。這就是為什麼這裡有各種演算法在起作用。以下兩個是您應該開始的。
- 線性迴歸:線性迴歸是機器學習中廣泛使用的演算法。它涉及從資料集中選擇一個關鍵變數來預測輸出變量,例如未來值。此演算法適用於具有連續標籤的情況,例如預測機場每天的航班數量。線性迴歸的表示為 y = ax + b。
- 嶺迴歸:嶺迴歸是另一種流行的機器學習演算法。它使用公式 y = Xβ + ϵ。在本例中,「y」表示因變數的 N*1 個觀測值向量,而「X」是迴歸量矩陣。迴歸係數以「β」表示,它是一個 N*1 向量,「ϵ」代表誤差向量。
您還可以使用其他迴歸技術,例如神經網路迴歸、套索迴歸、隨機森林、決策樹迴歸、SVM、多項式迴歸、高斯迴歸和 KNN 模型。
小數據集的機器學習模型
如果您正在處理小型資料集,則可以使用一些機器學習模型。
- Elastic Net: Elastic Net 是一種結合 Lasso (L1) 和 Ridge (L2) 回歸方法來處理具有多個相關特徵的場景的技術。它在 Lasso 的稀疏性和 Ridge 的正則化之間取得了平衡。 Elastic Net 用於小型資料集的原因是它在處理高度相關的預測變數時效果更好。此外,由於它結合了 L1 和 L2 正則化,因此與僅使用一種正則化形式的模型相比,它可以更有效地防止過度擬合。
- 單隱藏神經網路:在單一隱藏神經網路的情況下,只有一個輸入和一個輸出神經網路層。簡單性使得更容易實現和理解數據,這正是我們處理小數據集時所需要的。此外,它還可以更輕鬆地概括和解釋資訊。
各種其他模型可用於小型資料集,例如線性判別分析、二次判別分析和廣義線性模型,這些是最有用的模型。
大數據集的機器學習模型
處理大型資料集或大數據具有獲得有價值見解的潛力,但也帶來了獨特的挑戰。您可以使用我們之前討論的任何模型,但針對小型和大型資料集提到的模型除外。然而,這裡最大的問題是處理如此大量的數據。因此,這裡提到的模型和演算法旨在處理大量數據。
- 批次:批次處理是一種將大型資料集分為較小資料集(批次或資料包)的技術,並且在每個批次上增量地訓練模型。此方法有助於防止過度擬合(大型資料集的常見問題),並使訓練過程更易於管理。
- 分散式運算:分散式運算意味著將資料和任務分佈在多個機器或處理器上,以加快大型複雜機器學習模型的訓練速度。 Apache Hadoop 和 Apache Spark 等框架為分散式運算提供了強大的平台。
對於大型資料集,您還可以使用一些其他 ML 模型,例如線性迴歸和神經網路。
最好的機器學習模型是什麼?
各種機器學習模型包括樸素貝葉斯、KNN、隨機森林、Boosting、AdaBoot、線性迴歸等。但是,您必須選擇的模型取決於具體情況或您正在處理的項目。我們已經提到了上面的一些實例以及要使用的最佳模型和演算法。
4種機器學習模型是什麼?
四種機器學習模型分別是監督學習模型、無監督學習模型、半監督式學習模型、強化學習模型。每個都有自己的優點,所以它們應該一起使用。


發佈留言