人工智慧進入你的瀏覽器,速度比以往任何時候都快
我們想知道他們什麼時候才能在我們的瀏覽器中充分利用人工智慧的力量,顯然,時機已經到來。
我們正在討論一項名為 ONNX Runtime Web 的新功能,它使用 WebGPU 加速器,允許將 AI 模型直接建置到瀏覽器中並使其更快。快多了!
什麼是 ONNX 執行時間 Web?
為了解釋這一點,您需要知道 WebGPU 是引擎,就像 WebGL 一樣,但功能更強大,能夠處理更大的運算工作負載。它基本上是利用 GPU 的能力來執行人工智慧過程中所需的平行運算任務。
現在,讓我們來看看 ONNX Runtime Web,它是一個 JavaScript 程式庫,使 Web 開發人員能夠將 LLM 直接嵌入到 Web 瀏覽器中,並從 GPU 硬體加速中受益。
通常,大型法學碩士不太容易部署到瀏覽器中,因為它們需要大量記憶體和運算能力。
ONNX Runtime Web 的創新之處在於它支援 Microsoft 和 Intel 目前正在開發的 WebGPU 後端。
ONNX 執行時期 Web 的速度有多快?
為了證明他們的觀點,ONNX Runtime 團隊使用 Segment Anything 模型創建了一個演示,結果令人驚訝。
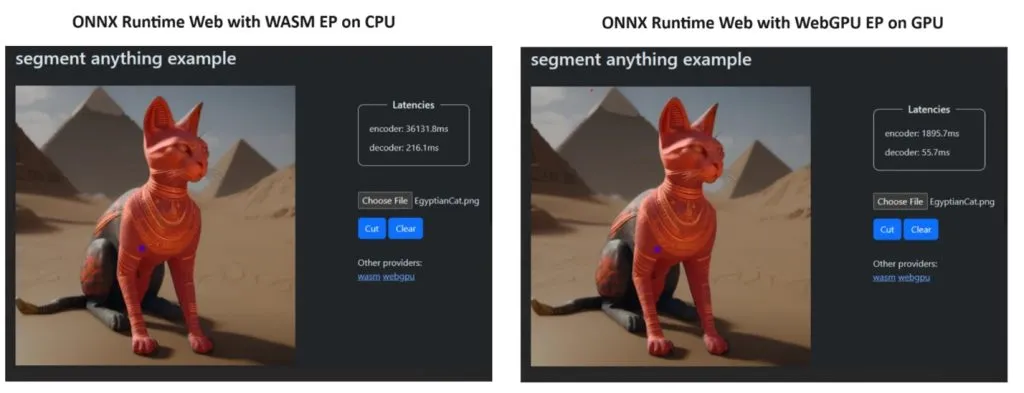
他們整合了 WASM EP 和 WebGPU EP,並使用 NVIDIA GeForce RTX 3060 和 Intel Core i9 PC。然後,他們比較了使用 CPU 的編碼器和新的 WebGPU,事實證明後者要快得多,如上面的螢幕截圖所示。
好消息是,WebGPU 已經嵌入到適用於 Windows、macOS 和 ChromeOS 的 Chrome 113 和 Edge 113 以及適用於 Android 的 Chrome 121 中。這表示您也可以在這些瀏覽器上使用 ONNX Runtime Web。
開發人員在其專案頁面上解釋如何嘗試 ONNX Runtime Web:
所以,現在我們已經準備好了一切,讓我們開始將一些強大的 LLM 部署到瀏覽器中!
您對新的 ONNX 執行時間 Web 有何看法?讓我們在下面的評論部分討論這一發展。
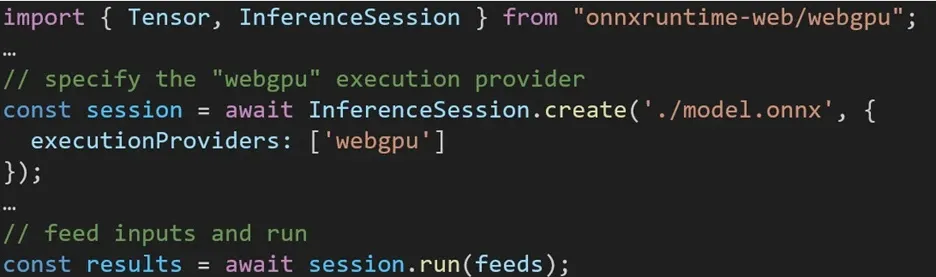
在 ONNX Runtime Web 中使用不同後端的體驗非常簡單。只需匯入相關套件並透過執行提供者設定與所需後端建立 ONNX 執行時間 Web 推理會話即可。我們的目標是簡化開發人員的流程,使他們能夠以最少的努力利用不同的硬體加速。
以下程式碼片段展示如何呼叫 ONNX Runtime Web API 以使用 WebGPU 推理模型。可存取其他ONNX 執行時間 Web 文件和範例以進行更深入的研究。
發佈留言