
VLOGGER AI: Agora crie um avatar realista a partir de uma foto e use sua voz para controlá-lo
Pesquisadores do Google estão trabalhando para tornar sua tecnologia de IA mais inteligente a cada dia. Um dos projetos de pesquisa mais recentes em que estão trabalhando é o VLOGGER.
VLOGGER é explicado como
De acordo com a postagem do blog no GitHub, essa abordagem permite a geração de vídeos de alta qualidade e duração desejável. Sem necessidade de treinamento para cada pessoa, não depende de recorte de detecção de rosto; pode gerar a imagem completa e levar em conta um amplo espectro, o que é importante para sintetizar os humanos que se comunicam.
No momento, o VLOGGER não está disponível para uso porque ainda está em desenvolvimento, mas quando chegar ao mercado poderá ser uma ótima maneira de se comunicar em uma videoconferência no Skype, Teams ou Slack.
O Google está bastante confiante no projeto e o testou em vários benchmarks; aqui está o que diz:
Como funciona o VLOGGER?
VLOGGER é uma estrutura que atua como um pipeline de dois estágios e funciona em uma arquitetura de difusão estocástica que transforma texto em imagem, vídeo e até modelos 3D, mas também adiciona um mecanismo de controle.
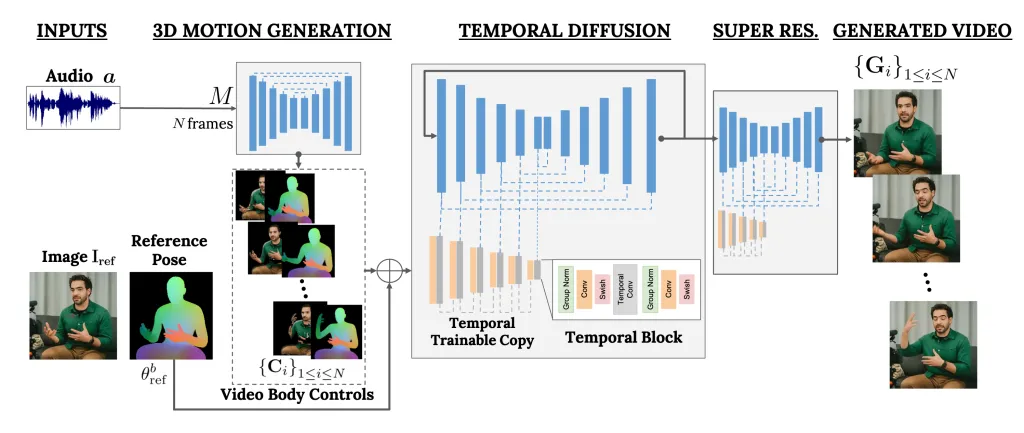
O primeiro passo é usar uma forma de onda de áudio como entrada para gerar controles intermediários de movimento corporal, como olhar e expressões faciais. Em seguida, a segunda rede utiliza um modelo de tradução temporal imagem a imagem para identificar esses movimentos e uma imagem de referência de uma pessoa para gerar frames para o vídeo.
Outra característica importante do VLOGGER é a capacidade de editar vídeos existentes. Pode gravar um vídeo e mudar a expressão da pessoa no vídeo.
Além disso, o VLOGGER também pode ajudar na tradução de vídeos; ele pode pegar um vídeo existente em um idioma específico e editar a área dos lábios e do rosto para torná-lo consistente com o novo áudio ou com idiomas diferentes.
Como o VLOGGER não é um produto, mas sim um projeto de pesquisa e não está completo, não é confiável. Sim, ele pode criar movimentos realistas, mas pode não ser capaz de corresponder ao modo como uma pessoa realmente se move. Dado o seu modelo de difusão, poderia apresentar um comportamento incomum.
Sua equipe também mencionou que não é versado em grandes movimentos ou ambientes diversos e só pode trabalhar em vídeos curtos.
Você acha que pode ser útil para você? Compartilhe suas opiniões com nossos leitores na seção de comentários abaixo
Avaliamos o VLOGGER em três benchmarks diferentes e mostramos que o modelo proposto supera outros métodos de última geração em qualidade de imagem, preservação de identidade e consistência temporal. Coletamos um novo e diversificado conjunto de dados MENTOR, uma ordem de magnitude maior que os anteriores (2.200 horas e 800.000 identidades, e um conjunto de testes de 120 horas e 4.000 identidades) no qual treinamos e eliminamos nossas principais contribuições técnicas. Relatamos o desempenho do VLOGGER em relação a múltiplas métricas de diversidade, mostrando que nossas escolhas arquitetônicas beneficiam o treinamento de um modelo justo e imparcial em escala.
Um método para geração de vídeo humano falante baseado em texto e áudio a partir de uma única imagem de entrada de uma pessoa, que se baseia no sucesso de modelos de difusão generativa recentes.
Nosso método consiste em 1) um modelo estocástico de difusão de movimento humano para 3D e 2) uma nova arquitetura baseada em difusão que aumenta modelos de texto para imagem com controles temporais e espaciais.


Deixe um comentário