
A IA entra no seu navegador e está mais rápida do que nunca
Estávamos nos perguntando quando eles usarão todo o poder da IA em nossos navegadores e, aparentemente, chegou a hora.
Estamos falando de um novo recurso chamado ONNX Runtime Web que usa o acelerador WebGPU que permite que modelos de IA sejam construídos diretamente no navegador e os tornem mais rápidos. Muito mais rápido!
O que é o ONNX Runtime Web?
Para explicar isso, você precisa saber que o WebGPU é um motor, como o WebGL, mas muito mais poderoso, capaz de lidar com cargas de trabalho computacionais maiores. Basicamente, ele aproveita o poder da GPU para executar tarefas computacionais paralelas necessárias em processos de IA.
Agora, chegando ao ONNX Runtime Web, é uma biblioteca JavaScript que permite aos desenvolvedores da web incorporar LLMs diretamente nos navegadores da web e se beneficiar da aceleração de hardware da GPU.
Normalmente, grandes LLMs não são tão facilmente implantados em navegadores porque requerem muita memória e poder computacional.
A inovação do ONNX Runtime Web é permitir o back-end WebGPU que a Microsoft e a Intel estão desenvolvendo no momento.
Qual é a velocidade do ONNX Runtime Web?
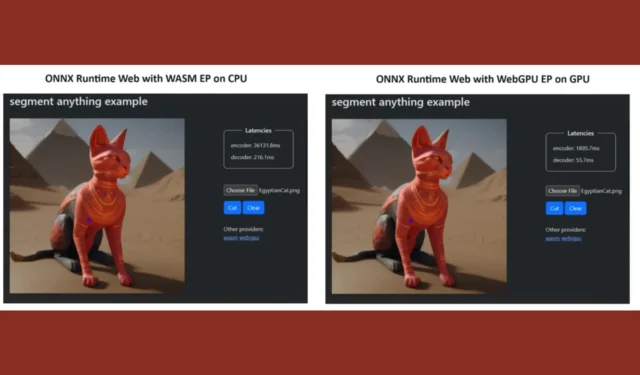
Para provar seu ponto de vista, a equipe do ONNX Runtime criou uma demonstração usando o modelo Segment Anything e os resultados foram surpreendentes.
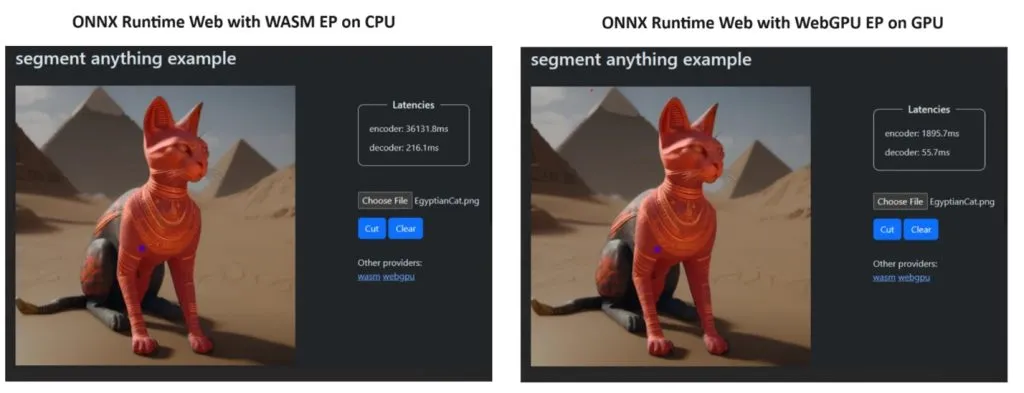
Eles incorporaram WASM EP e WebGPU EP e usaram um PC NVIDIA GeForce RTX 3060 e Intel Core i9. Em seguida, compararam o codificador usando a CPU e o novo WebGPU e este último se mostrou bem mais rápido, como mostra a imagem acima.
A boa notícia é que o WebGPU já está integrado ao Chrome 113 e Edge 113 para Windows, macOS e ChromeOS e Chrome 121 para Android. Isso significa que você também pode jogar com ONNX Runtime Web nesses navegadores.
Os desenvolvedores explicaram como experimentar o ONNX Runtime Web na página do projeto:
Então, agora que temos tudo pronto, vamos começar a implantar alguns LLMs poderosos nos navegadores!
O que você acha do novo ONNX Runtime Web? Vamos falar sobre esse desenvolvimento na seção de comentários abaixo.
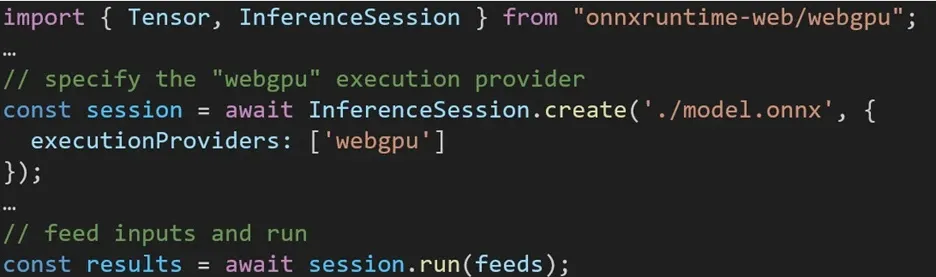
A experiência de utilização de diferentes back-ends no ONNX Runtime Web é direta. Basta importar o pacote relevante e criar uma sessão de inferência da Web ONNX Runtime com o back-end necessário por meio da configuração do Provedor de Execução. Nosso objetivo é simplificar o processo para os desenvolvedores, permitindo-lhes aproveitar diferentes acelerações de hardware com o mínimo de esforço.
O trecho de código a seguir mostra como chamar a API Web ONNX Runtime para inferir um modelo com WebGPU. Documentação e exemplos adicionais do ONNX Runtime Web estão acessíveis para um aprofundamento.


Deixe um comentário