
Melhores modelos de aprendizado de máquina para conhecer
Se você quer alavancar o poder da inteligência artificial e do aprendizado de máquina, você deve estar familiarizado com alguns dos melhores Modelos de Aprendizado de Máquina. Existem dezenas de modelos de aprendizado de máquina, então pode ser um pouco confuso escolher modelos de aprendizado de máquina para um projeto. Nesta postagem, falaremos sobre alguns dos melhores Modelos de Aprendizado de Máquina que você pode usar dependendo do seu projeto.
Melhores modelos de aprendizado de máquina para conhecer
Temos a lista de modelos e algoritmos de aprendizado de máquina para os seguintes projetos, instâncias e cenários.
Modelos de aprendizado de máquina para previsão de séries temporais
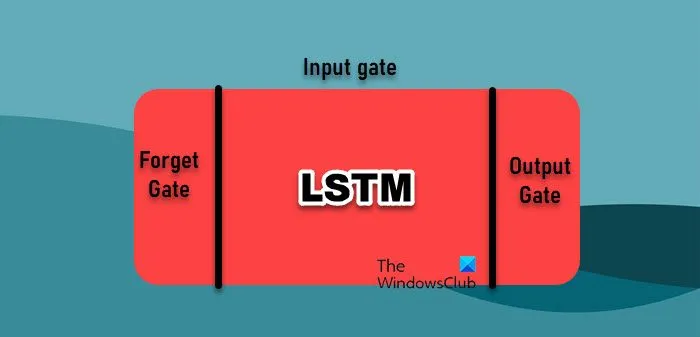
Na análise de dados, a previsão de séries temporais depende de vários algoritmos de machine learning, cada um com seus próprios pontos fortes. No entanto, falaremos sobre dois dos mais usados.
- Rede de Memória Longa de Curto Prazo: Redes de Memória Longa de Curto Prazo (LSTM) são um tipo de Rede Neural Recorrente (RNN) que são particularmente eficazes em aprender com sequências, tornando-as bem adequadas para dados de séries temporais. Ao contrário das RNNs tradicionais, que lutam com dependências de longo prazo devido ao problema do gradiente de desaparecimento, as LSTMs podem reter informações por longos períodos. Isso é realizado por meio de sua arquitetura exclusiva, que inclui portas para gerenciar o fluxo de informações, permitindo que capturem padrões intrincados em dados de séries temporais.
- Randon Forest: Random Forest é um método de aprendizado de conjunto (aqui dois ou mais aprendizes). Durante o treinamento, ele constrói várias árvores de decisão e então faz a média de suas previsões. Embora não tenha sido originalmente criado para séries temporais, ele pode ser ajustado para previsão incluindo variáveis defasadas. Random Forest pode lidar com muitos recursos e é menos provável que se ajuste demais, o que o torna uma escolha forte para conjuntos de dados complexos.
Você pode integrar esses dois modelos e alguns outros, como VAR, ARIRA e Prophet Models, para obter o melhor resultado possível.
Modelos de Aprendizado de Máquina para Previsão de Ações

Ações são aleatórias, mas, ao mesmo tempo, essa aleatoriedade também tem um padrão. Se seu projeto tem como objetivo fazer uma previsão de ações, recomendamos usar um ou ambos os modelos mencionados abaixo.
- Árvore de decisão: Uma árvore de decisão é um tipo de fluxograma que ajuda na tomada de decisões ou previsões. Ela tem nós para decisões ou testes em atributos, ramificações para os resultados dessas decisões e nós folha para resultados finais ou previsões. Cada nó interno representa um teste em um atributo, cada ramificação representa o resultado do teste e cada nó folha representa um rótulo de classe ou um valor contínuo.
- Rede Neural: Redes neurais são modelos de computador que imitam as funções intrincadas do cérebro humano. Elas consistem em nós ou neurônios interconectados que processam e aprendem com dados. Isso permite tarefas como reconhecimento de padrões e tomada de decisão em aprendizado de máquina. Se você treiná-los bem, eles podem funcionar como mestres de ações.
No entanto, você precisa se lembrar que descobrir padrões de ações pode ser muito complicado, então não se deve confiar muito nesses modelos e incorporar outros, como Randon Forest e LSTM.
Modelos de Aprendizado de Máquina para Classificações Multiclasse
Agora, vamos discutir um dos trabalhos mais comuns de aprendizado de máquina: classificação multiclasse. Aqui, nosso trabalho é esboçar um modelo que, com a ajuda de dados anteriores, pode analisar uma informação e classificá-la. O modelo analisa o conjunto de dados de treinamento para encontrar padrões exclusivos para cada classe. Ele então usa esses padrões para prever a categoria de dados futuros. Dois dos algoritmos e modelos mais comuns são mencionados abaixo.
- SVMs são boas em trabalhar com muitas informações e encontrar padrões, então são úteis em muitas áreas diferentes. Em virtude de todas essas facilidades que ele fornece, ele pode ser usado para monitorar dados e classificá-los.
- Inclui Multinomial Naive Bayes, Bernoulli Naive Bayes e Gaussian Naive Bayes. Classificadores Naive Bayes são um grupo de algoritmos de classificação baseados no Teorema de Bayes. Eles não são apenas um algoritmo, mas sim uma família de algoritmos que seguem o mesmo princípio: cada par de características sendo classificadas é independente uma da outra.
Você também pode usar a Rede Neural (os detalhes mencionados acima) para esse recurso.
Modelo de Aprendizado de Máquina para Regressão

A regressão é usada para prever valor contínuo, um dos recursos mais necessários. É por isso que há vários algoritmos em jogo aqui. Os dois seguintes são aqueles com os quais você deve começar.
- Regressão Linear: A regressão linear é um algoritmo amplamente usado em aprendizado de máquina. Ela envolve selecionar uma variável-chave do conjunto de dados para prever as variáveis de saída, como valores futuros. Este algoritmo é adequado para casos com rótulos contínuos, como prever o número de voos diários de um aeroporto. A representação da regressão linear é y = ax + b.
- Regressão de Ridge: Regressão de Ridge é outro algoritmo popular de ML. Ele usa a fórmula y = Xβ + ϵ. Neste caso, ‘y’ representa o vetor N*1 de observações para a variável dependente, enquanto ‘X’ é a matriz de regressores. Os coeficientes de regressão são denotados por ‘β’, que é um vetor N*1, e ‘ϵ’ representa o vetor de erros.
Existem outras técnicas de regressão que você pode usar, como regressão de rede neural, regressão Lasso, floresta aleatória, regressão de árvore de decisão, SVM, regressão polinomial, regressão gaussiana e modelo KNN.
Modelo de Aprendizado de Máquina para Pequenos Conjuntos de Dados
Se você estiver lidando com um pequeno conjunto de dados, há alguns modelos de ML que você pode usar.
- Elastic Net: Elastic Net é uma técnica que combina os métodos de regressão Lasso (L1) e Ridge (L2) para lidar com cenários com vários recursos correlacionados. Ela atinge um equilíbrio entre a dispersão de Lasso e a regularização de Ridge. A razão pela qual Elastic Net é usada para pequenos conjuntos de dados é que ela é melhor ao lidar com preditores altamente correlacionados. Além disso, como ela combina regularização L1 e L2, ela pode evitar que você faça overfitting de forma mais eficaz em comparação com modelos que usam apenas uma forma de regularização.
- Single Hidden Neural Network: No caso de Single Hidden Neural Network, há apenas uma camada de rede neural de entrada e uma de saída. A simplicidade torna mais fácil implementar e entender dados, que é o que precisamos ao lidar com pequenos conjuntos de dados. Além disso, torna mais fácil generalizar e interpretar informações.
Vários outros modelos podem ser usados para pequenos conjuntos de dados, como análise discriminante linear, análise discriminante quadrática e modelo linear generalizado, que são alguns dos mais úteis.
Modelo de aprendizado de máquina para grandes conjuntos de dados
Processar grandes conjuntos de dados, ou big data, tem o potencial de insights valiosos, mas apresenta desafios únicos. Você pode usar qualquer um dos modelos que discutimos anteriormente, exceto os mencionados para os conjuntos de dados pequenos e grandes. No entanto, o maior problema aqui é processar uma quantidade tão grande de dados. Então, os modelos e algoritmos mencionados aqui visam processar uma quantidade enorme de dados.
- Processamento em lote: O processamento em lote é uma técnica em que um grande conjunto de dados é dividido em conjuntos de dados menores (lotes ou pacotes), e o modelo é treinado em cada lote incrementalmente. Este método ajuda a evitar overfitting, um problema comum com grandes conjuntos de dados, e torna o processo de treinamento mais gerenciável.
- Computação Distribuída: Computação distribuída significa espalhar dados e tarefas por várias máquinas ou processadores para acelerar o treinamento de modelos de aprendizado de máquina grandes e complexos. Frameworks como Apache Hadoop e Apache Spark fornecem plataformas fortes para computação distribuída.
Você também pode usar alguns outros modelos de ML, como regressão linear e redes neurais, para grandes conjuntos de dados.
Qual é o melhor modelo de aprendizado de máquina?
Vários modelos de machine learning incluem Naive Bayes, KNN, Random Forest, Boosting, AdaBoot, Linear Regression e mais. No entanto, o modelo que você deve escolher depende da situação ou do projeto em que você está trabalhando. Mencionamos algumas das instâncias acima e os melhores modelos e algoritmos para usar.
Quais são os 4 modelos de aprendizado de máquina?
Os quatro modelos de machine learning são o modelo de aprendizado supervisionado, o modelo de aprendizado não supervisionado, o modelo de aprendizado semissupervisionado e o modelo de aprendizado por reforço. Cada um tem suas próprias vantagens, então todos devem ser usados juntos.


Deixe um comentário