
Najlepsze modele uczenia maszynowego, które warto znać
Jeśli chcesz wykorzystać moc sztucznej inteligencji i uczenia maszynowego, musisz znać niektóre z najlepszych modeli uczenia maszynowego. Istnieją dziesiątki modeli uczenia maszynowego, więc wybór modeli uczenia maszynowego do projektu może być nieco mylący. W tym poście omówimy niektóre z najlepszych modeli uczenia maszynowego, których możesz użyć w zależności od swojego projektu.
Najlepsze modele uczenia maszynowego, które warto znać
Mamy listę modeli i algorytmów uczenia maszynowego dla następujących projektów, instancji i scenariuszy.
Modele uczenia maszynowego do prognozowania szeregów czasowych
W analizie danych prognozowanie szeregów czasowych opiera się na różnych algorytmach uczenia maszynowego, z których każdy ma swoje mocne strony. Jednak omówimy dwa z najczęściej używanych.
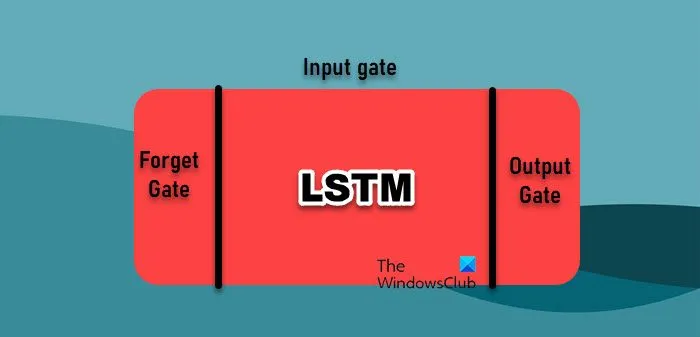
- Sieć pamięci długoterminowej krótkoterminowej: Sieci pamięci długoterminowej krótkoterminowej (LSTM) to rodzaj rekurencyjnej sieci neuronowej (RNN), która jest szczególnie skuteczna w uczeniu się z sekwencji, co czyni ją dobrze przystosowaną do danych szeregów czasowych. W przeciwieństwie do tradycyjnych sieci RNN, które zmagają się z długoterminowymi zależnościami z powodu problemu zanikającego gradientu, sieci LSTM mogą przechowywać informacje przez długie okresy. Jest to możliwe dzięki ich unikalnej architekturze, która obejmuje bramy do zarządzania przepływem informacji, umożliwiając im wychwytywanie skomplikowanych wzorców w danych szeregów czasowych.
- Randon Forest: Random Forest to metoda uczenia się zespołowego (tutaj dwóch lub więcej uczących się). Podczas treningu buduje wiele drzew decyzyjnych, a następnie uśrednia ich przewidywania. Chociaż pierwotnie nie była przeznaczona do szeregów czasowych, można ją dostosować do prognozowania, uwzględniając zmienne opóźnione. Random Forest może obsługiwać wiele cech i jest mniej prawdopodobne, że będzie nadmiernie dopasowywana, co czyni ją dobrym wyborem w przypadku złożonych zestawów danych.
Aby uzyskać możliwie najlepsze rezultaty, można zintegrować te dwa modele, a także kilka innych, np. VAR, ARIRA i Prophet Models.
Modele uczenia maszynowego do prognozowania cen akcji

Akcje są losowe, ale jednocześnie ta losowość ma również pewien wzór. Jeśli Twój projekt ma na celu dokonanie prognozy akcji, zalecamy użycie jednego lub obu modeli wymienionych poniżej.
- Drzewo decyzyjne: Drzewo decyzyjne to rodzaj schematu blokowego, który pomaga w podejmowaniu decyzji lub przewidywań. Ma węzły dla decyzji lub testów atrybutów, gałęzie dla wyników tych decyzji i węzły liściowe dla końcowych wyników lub przewidywań. Każdy węzeł wewnętrzny reprezentuje test atrybutu, każda gałąź reprezentuje wynik testu, a każdy węzeł liściowy reprezentuje etykietę klasy lub wartość ciągłą.
- Sieć neuronowa: Sieci neuronowe to modele komputerowe, które imitują skomplikowane funkcje ludzkiego mózgu. Składają się z połączonych węzłów lub neuronów, które przetwarzają i uczą się z danych. Umożliwia to zadania takie jak rozpoznawanie wzorców i podejmowanie decyzji w uczeniu maszynowym. Jeśli dobrze je wyszkolisz, mogą działać jako mistrzowie akcji.
Należy jednak pamiętać, że rozszyfrowywanie wzorców giełdowych może być bardzo trudne, dlatego nie należy zbytnio polegać na tych modelach i lepiej włączyć inne, np. Randon Forest i LSTM.
Modele uczenia maszynowego dla klasyfikacji wieloklasowych
Teraz omówmy jedno z najczęstszych zadań uczenia maszynowego: klasyfikację wieloklasową. Tutaj naszym zadaniem jest opracowanie modelu, który przy pomocy poprzednich danych może przyjrzeć się fragmentowi informacji i sklasyfikować go. Model analizuje zbiór danych treningowych, aby znaleźć unikalne wzorce dla każdej klasy. Następnie wykorzystuje te wzorce do przewidywania kategorii przyszłych danych. Poniżej wymieniono dwa z najczęstszych algorytmów i modeli.
- SVM dobrze radzą sobie z pracą z dużą ilością informacji i wyszukiwaniem wzorców, więc są przydatne w wielu różnych obszarach. Dzięki wszystkim tym udogodnieniom, które zapewniają, można ich używać do monitorowania danych i ich klasyfikowania.
- Obejmuje ona Multinomial Naive Bayes, Bernoulli Naive Bayes i Gaussian Naive Bayes. Klasyfikatory Naive Bayes to grupa algorytmów klasyfikacyjnych opartych na twierdzeniu Bayesa. Nie są one tylko jednym algorytmem, ale raczej rodziną algorytmów, które wszystkie podążają za tą samą zasadą: każda para klasyfikowanych cech jest niezależna od siebie.
Do tej funkcji można również wykorzystać sieć neuronową (szczegóły podane powyżej).
Model uczenia maszynowego dla regresji

Regresja jest używana do przewidywania wartości ciągłej, jednej z najbardziej potrzebnych cech. Dlatego w grę wchodzą różne algorytmy. Poniższe dwa to te, od których powinieneś zacząć.
- Regresja liniowa: Regresja liniowa jest szeroko stosowanym algorytmem w uczeniu maszynowym. Polega na wybraniu kluczowej zmiennej ze zbioru danych w celu przewidzenia zmiennych wyjściowych, takich jak wartości przyszłe. Ten algorytm nadaje się do przypadków z ciągłymi etykietami, takimi jak przewidywanie liczby codziennych lotów z lotniska. Reprezentacja regresji liniowej to y = ax + b.
- Regresja grzbietowa: Regresja grzbietowa to kolejny popularny algorytm ML. Używa wzoru y = Xβ + ϵ. W tym przypadku „y” reprezentuje wektor N*1 obserwacji dla zmiennej zależnej, podczas gdy „X” jest macierzą regresorów. Współczynniki regresji są oznaczone jako „β”, który jest wektorem N*1, a „ϵ” oznacza wektor błędów.
Istnieją inne techniki regresji, z których możesz skorzystać, takie jak regresja sieci neuronowych, regresja Lasso, regresja losowego lasu, regresja drzewa decyzyjnego, SVM, regresja wielomianowa, regresja Gaussa i model KNN.
Model uczenia maszynowego dla małych zestawów danych
Jeśli masz do czynienia z niewielkim zbiorem danych, możesz skorzystać z kilku modeli uczenia maszynowego.
- Elastic Net: Elastic Net to technika łącząca metody regresji Lasso (L1) i Ridge (L2) w celu obsługi scenariuszy z wieloma skorelowanymi cechami. Utrzymuje równowagę między rzadkością Lasso a regularyzacją Ridge’a. Powodem, dla którego Elastic Net jest używany w przypadku małych zestawów danych, jest to, że lepiej sprawdza się w przypadku wysoce skorelowanych predyktorów. Ponadto, ponieważ łączy regularyzację L1 i L2, może skuteczniej zapobiegać nadmiernemu dopasowaniu w porównaniu z modelami, które wykorzystują tylko jedną formę regularizacji.
- Pojedyncza ukryta sieć neuronowa: W przypadku pojedynczej ukrytej sieci neuronowej istnieje tylko jedna warstwa sieci neuronowej wejściowej i jedna wyjściowa. Prostota ułatwia implementację i zrozumienie danych, czego potrzebujemy, mając do czynienia z małymi zbiorami danych. Ponadto ułatwia uogólnianie i interpretowanie informacji.
Do małych zbiorów danych można stosować różne inne modele, takie jak liniowa analiza dyskryminacyjna, kwadratowa analiza dyskryminacyjna i uogólniony model liniowy, które należą do najprzydatniejszych.
Model uczenia maszynowego dla dużych zbiorów danych
Przetwarzanie dużych zbiorów danych, czyli big data, ma potencjał na cenne spostrzeżenia, ale stwarza wyjątkowe wyzwania. Możesz użyć dowolnego z modeli, które omówiliśmy wcześniej, z wyjątkiem tych wymienionych dla małych i dużych zbiorów danych. Jednak największym problemem jest tutaj przetwarzanie tak dużej ilości danych. Tak więc modele i algorytmy wymienione tutaj mają na celu przetwarzanie ogromnej ilości danych.
- Przetwarzanie wsadowe: Przetwarzanie wsadowe to technika, w której duży zestaw danych jest dzielony na mniejsze zestawy danych (partie lub pakiety), a model jest trenowany na każdym pakiecie przyrostowo. Ta metoda pomaga zapobiegać nadmiernemu dopasowaniu, powszechnemu problemowi dużych zestawów danych, i sprawia, że proces trenowania jest bardziej zarządzalny.
- Rozproszone przetwarzanie: Rozproszone przetwarzanie oznacza rozproszenie danych i zadań na kilku maszynach lub procesorach w celu przyspieszenia szkolenia dużych i złożonych modeli uczenia maszynowego. Ramy takie jak Apache Hadoop i Apache Spark zapewniają solidne platformy dla rozproszonego przetwarzania.
W przypadku dużych zbiorów danych można również wykorzystać inne modele uczenia maszynowego, takie jak regresja liniowa i sieci neuronowe.
Jaki jest najlepszy model uczenia maszynowego?
Różne modele uczenia maszynowego obejmują Naive Bayes, KNN, Random Forest, Boosting, AdaBoot, Linear Regression i inne. Jednak model, który musisz wybrać, zależy od sytuacji lub projektu, nad którym pracujesz. Wspomnieliśmy o niektórych z powyższych przypadków oraz najlepszych modelach i algorytmach do użycia.
Jakie są 4 modele uczenia maszynowego?
Cztery modele uczenia maszynowego to model uczenia nadzorowanego, model uczenia nienadzorowanego, model uczenia półnadzorowanego i model uczenia wzmacniającego. Każdy z nich ma swoje zalety, więc wszystkie powinny być używane razem.


Dodaj komentarz