
Opera staje się pierwszą dużą przeglądarką integrującą lokalne modele sztucznej inteligencji
Co wiedzieć
- Opera jest pierwszą przeglądarką, która dodała wbudowaną obsługę lokalnych LLM, jest ich około 150.
- Lokalne LLM są idealne do zwiększenia prywatności i bezpieczeństwa, a także dostępu offline do modeli AI. Ich prędkość zależy jednak od możliwości Twojej maszyny.
- Dostęp do lokalnych modeli sztucznej inteligencji jest dostępny w strumieniu deweloperskim Opery One.
Opera integruje obsługę 150 lokalnych wariantów LLM (Large Language Model) ze strumieniem deweloperskim Opera One – firmy przeglądarki zintegrowanej ze sztuczną inteligencją. Dodanie eksperymentalnej lokalnej obsługi sztucznej inteligencji jest pierwszym rozwiązaniem w przeglądarce i umożliwia łatwy dostęp do modeli sztucznej inteligencji bezpośrednio z samej przeglądarki.
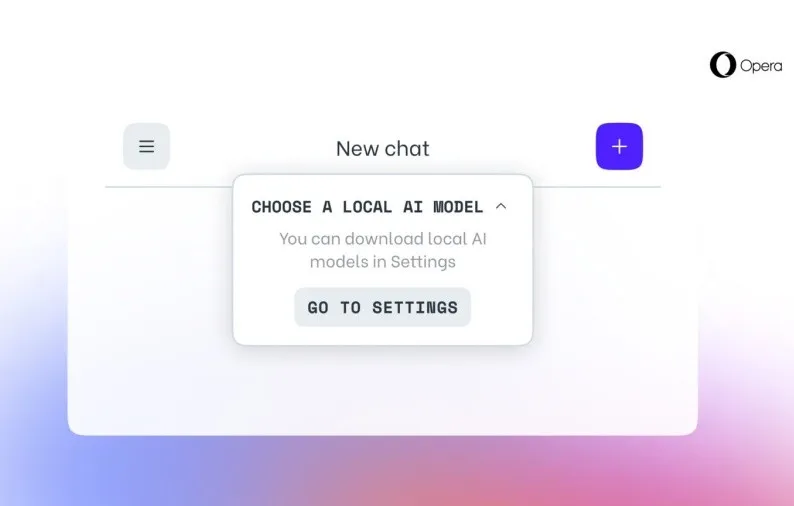
Do bardziej znanych lokalnych LLM w Operze One należą m.in. Llama z Meta, Gemma z Google, Vicuna i Mixtral z Mistral AI. Są one dodatkiem do chatbota Aria Opery.
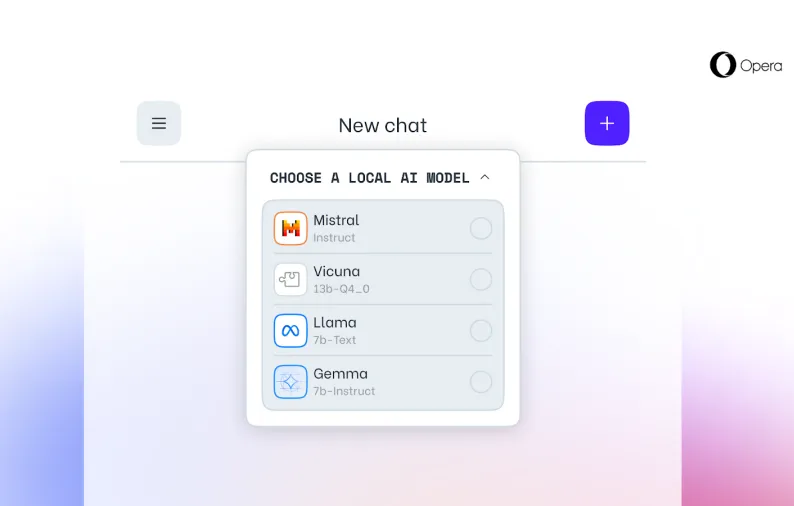
Użytkownicy Opera One Developer mogą zacząć od aktualizacji przeglądarki do najnowszej wersji, następnie wybrać modele, które chcą przetestować, aktywować nową funkcję i pobrać lokalny LLM na swój komputer. Typowy LLM będzie wymagał od 2 do 10 GB pamięci. Po pobraniu będziesz mógł przełączyć się i używać lokalnego LLM zamiast Arii.
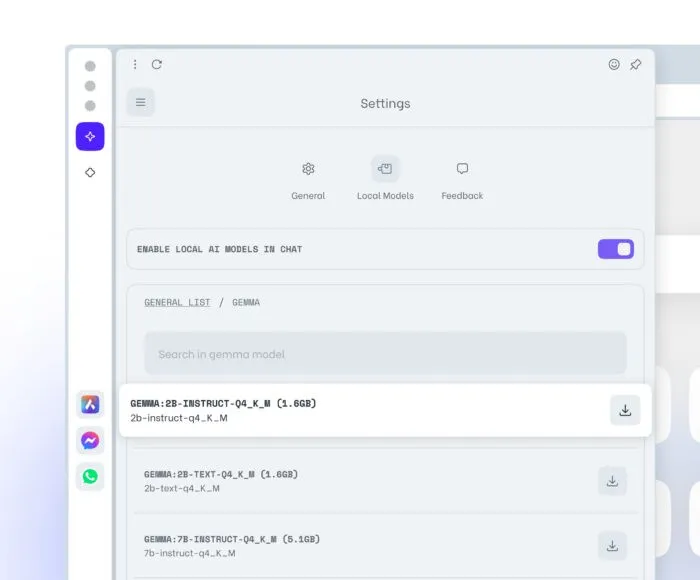
Lokalne LLM mają kilka zalet, takich jak większa prywatność i bezpieczeństwo, ponieważ dane nie opuszczają Twojego komputera, korzystanie z Internetu w trybie offline i ogólnie ulepszona obsługa przeglądarki. Jedyną wadą, jaką może mieć lokalny LLM, jest to, że może powolnie dostarczać dane wyjściowe w porównaniu z LLM opartymi na serwerze, ponieważ przetwarzanie jest całkowicie zależne od możliwości sprzętowych komputera. Dlatego nawet jeśli działałoby to dobrze na większości nowoczesnych maszyn, starsze urządzenia mogły odczuć ograniczenie zasobów.
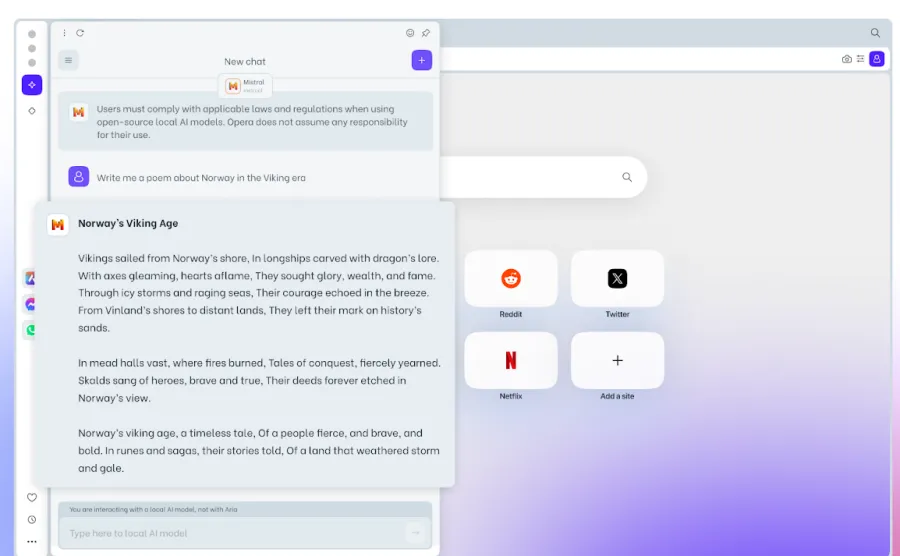
Niemniej jednak integracja lokalnych modeli sztucznej inteligencji z samą przeglądarką jest dla Opery dużym krokiem naprzód i być może stanie się to trendem w innych głównych przeglądarkach.


Dodaj komentarz