
VLOGGER AI: Teraz utwórz realistyczny awatar ze zdjęcia i steruj nim za pomocą głosu
Naukowcy z Google każdego dnia pracują nad ulepszaniem technologii AI. Jednym z najnowszych projektów badawczych, nad którym pracują, jest VLOGGER.
VLOGGER jest wyjaśniony jako
Jak wynika z wpisu na blogu na GitHubie, takie podejście pozwala na generowanie wysokiej jakości filmów o pożądanej długości. Bez potrzeby szkolenia każdej osoby nie jest to zależne od kadrowania z wykorzystaniem wykrywania twarzy; może wygenerować pełny obraz i uwzględnić szerokie spektrum, co jest ważne dla syntezy komunikujących się ludzi.
W tej chwili VLOGGER nie jest dostępny do użytku, ponieważ jest wciąż w fazie rozwoju, ale kiedy trafi na rynek, może być świetnym sposobem komunikacji podczas wideokonferencji na Skype, Teams lub Slack.
Google ma duże zaufanie do projektu i przetestował go w różnych testach porównawczych; oto co napisano:
Jak działa VLOGGER?
VLOGGER to framework, który działa jak dwuetapowy potok i działa w oparciu o architekturę dyfuzji stochastycznej, która przekształca tekst w obraz, wideo, a nawet modele 3D, ale dodaje również mechanizm kontrolny.
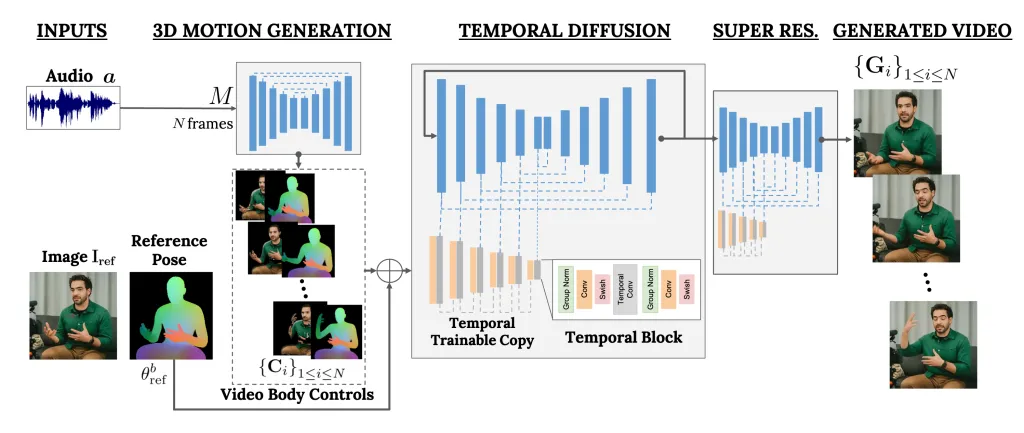
Pierwszym krokiem jest przyjęcie kształtu fali dźwiękowej jako sygnału wejściowego w celu wygenerowania pośrednich elementów sterujących ruchem ciała, takich jak spojrzenie i mimika. Następnie druga sieć wykorzystuje tymczasowy model translacji obrazu na obraz w celu identyfikacji tych ruchów oraz obraz referencyjny osoby w celu wygenerowania klatek wideo.
Kolejną ważną funkcją VLOGGERA jest możliwość edycji istniejących filmów. Może nagrać film i zmienić wyraz osoby na filmie.
Ponadto VLOGGER może również pomóc w tłumaczeniu wideo; może przejąć istniejący film w określonym języku i edytować obszar ust i twarzy, aby był spójny z nowym dźwiękiem lub innymi językami.
Ponieważ VLOGGER nie jest produktem, lecz projektem badawczym i nie jest ukończony, nie można na nim polegać. Tak, może stworzyć realistyczny ruch, ale może nie być w stanie odzwierciedlić rzeczywistego ruchu danej osoby. Biorąc pod uwagę model dyfuzji, może wykazywać niezwykłe zachowanie.
Jego zespół wspomniał również, że nie jest zaznajomiony z dużymi ruchami ani różnorodnymi środowiskami i może pracować tylko w przypadku krótkich filmów.
Czy myślisz, że mogłoby to być dla Ciebie pomocne? Podziel się swoimi opiniami z naszymi czytelnikami w sekcji komentarzy poniżej
Oceniamy VLOGGER na trzech różnych poziomach odniesienia i pokazujemy, że proponowany model przewyższa inne najnowocześniejsze metody pod względem jakości obrazu, zachowania tożsamości i spójności czasowej. Gromadzimy nowy i zróżnicowany zbiór danych MENTOR o jeden rząd wielkości większy niż poprzednie (2200 godzin i 800 000 tożsamości oraz zestaw testowy obejmujący 120 godzin i 4000 tożsamości), na podstawie którego szkolimy i ograniczamy nasz główny wkład techniczny. Raportujemy wydajność VLOGGERa w odniesieniu do wielu wskaźników różnorodności, pokazując, że nasze wybory architektoniczne przynoszą korzyści w szkoleniu uczciwego i bezstronnego modelu na dużą skalę.
Metoda generowania wideo mówiącego człowieka w oparciu o tekst i dźwięk na podstawie pojedynczego obrazu wejściowego osoby, która opiera się na sukcesie najnowszych modeli dyfuzji generatywnej.
Nasza metoda składa się z 1) stochastycznego modelu dyfuzji ruchu człowieka na ruch 3D oraz 2) nowatorskiej architektury opartej na dyfuzji, która rozszerza modele tekstu na obraz o kontrolę zarówno czasową, jak i przestrzenną.


Dodaj komentarz