
Reddit blokkeert Bing en andere zoekmachines om zijn data te scrapen – maar Google niet
Wat te weten
- Reddit heeft zijn robots.txt-bestand bijgewerkt om te voorkomen dat Bing en andere zoekmachines de site crawlen.
- Reddit beweert dat de repressie het gevolg is van mislukte overeenkomsten met zoekmachines en bedrijven die niet bereid zijn om afdwingbare beloftes te doen over hun gebruik van Reddit-content.
- Google is de enige grote zoekmachine die recente content van Reddit in de zoekresultaten kan weergeven, naar verluidt dankzij hun deal van 60 miljoen dollar.
Reddit intensiveert haar inspanningen om te voorkomen dat webcrawlers haar data gebruiken. Als gevolg van haar strenge aanpak kan momenteel geen enkele grote zoekmachine, of het nu Bing of DuckDuckGo is, recente Reddit-berichten en -reacties in hun zoekresultaten weergeven. Geen enkele behalve Google.
Dus als je hebt geprobeerd om te zoeken naar recente Reddit-resultaten in je zoekmachinequery, zul je helaas tekortschieten. Vergelijk de zoekresultaten op Bing en Google voor dezelfde query over een recente nieuwsdiscussie:
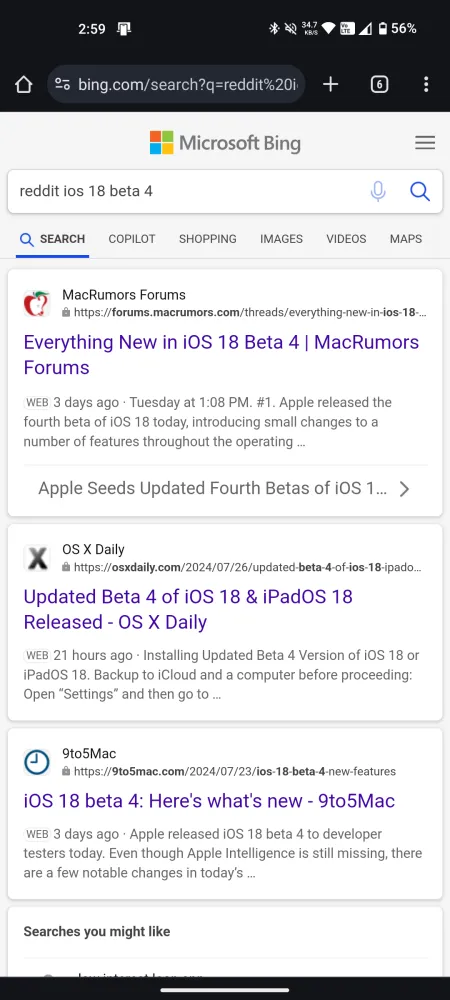
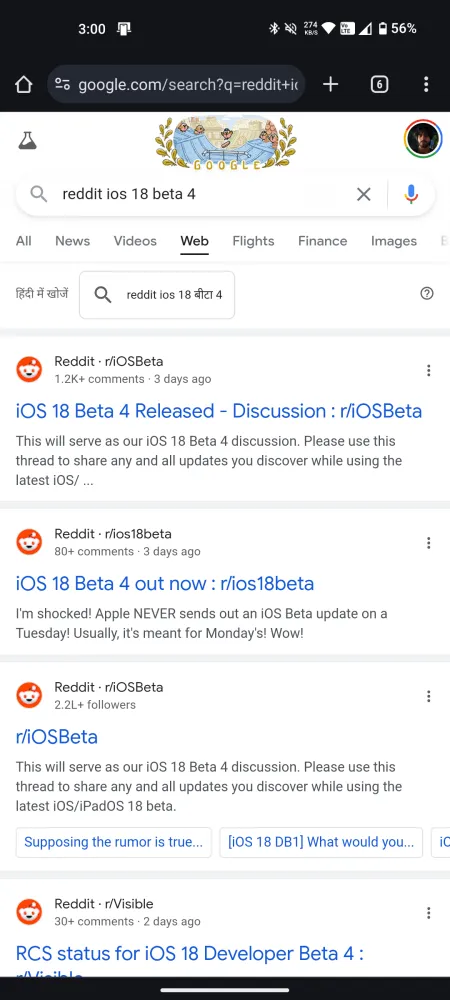
Reddit is de laatste tijd steeds meer beschermend geworden over zijn data, en dat is begrijpelijk. Omdat het een populair communityforum is waar mensen samenkomen om te discussiëren en te praten over hun interesses, is Reddit een ware goudmijn voor AI-training. Maar Reddit begrijpt, net als de AI-bedrijven, wat een onschatbare bron de website is in een tijd waarin AI-chatbots het web overnemen.
Om zijn belangen te beschermen, heeft Reddit zijn robots.txt-bestand bijgewerkt om te voorkomen dat webcrawlers toegang krijgen tot de website. Deze stap volgt op verschillende mislukte pogingen om een overeenkomst te bereiken met de verschillende zoekmachines over hun gebruik van Reddit’s content. Het hard aanpakken van zoekmachines en het stoppen van het scrapen van data is een duidelijk signaal dat degenen die geen overeenkomst hebben, geen toegang zouden moeten hebben tot Reddit-content.
Op dit moment is Google de enige grote zoekmachine die Reddit-berichten en -reacties in de zoekresultaten kan weergeven. En dat is ook geen toeval. Hoewel een woordvoerder van Reddit in een verklaring zei dat “[d]it helemaal niets te maken heeft met onze recente samenwerking met Google”, is het niet eenvoudig om voorbij de deal van $ 60 miljoen te kijken waarmee Google zijn AI-model op Reddits gegevens kon trainen. Naar verluidt omvatte de deal ook realtime toegang tot Reddits content.
De boodschap van Reddit is duidelijk genoeg: betaal of mis het. De meeste bedrijven, waaronder Microsoft, hebben toegegeven. In een verklaring zei Microsoft:
“We respecteren de robots.txt-standaard. Bing stopte met het crawlen van Reddit nadat ze hun bijgewerkte robots.txt-bestand op 1 juli implementeerden, wat alle crawlen van hun site verbiedt.”
Degenen die niet-Google zoekmachines gebruiken, zijn duidelijk in het nadeel, voornamelijk omdat Reddit’s eigen zoekfunctie niet zo goed werkt als zoekmachines bij het vinden van relevante content. Als u op dit moment recente resultaten van Reddit wilt krijgen met behulp van de truc “site:reddit.com” of door de query toe te voegen met het woord ‘Reddit’, moet u eerst Google openen.


Geef een reactie