
Beste Machine Learning-modellen om te kennen
Als u de kracht van kunstmatige intelligentie en machine learning wilt benutten, moet u bekend zijn met enkele van de beste Machine Learning-modellen. Er zijn tientallen machine learning-modellen, dus het kan een beetje verwarrend zijn bij het kiezen van machine learning-modellen voor een project. In dit bericht zullen we het hebben over enkele van de beste Machine Learning-modellen die u kunt gebruiken, afhankelijk van uw project.
Beste Machine Learning-modellen om te kennen
We hebben een lijst met machine learning-modellen en -algoritmen voor de volgende projecten, instanties en scenario’s.
Machine Learning-modellen voor tijdreeksvoorspellingen
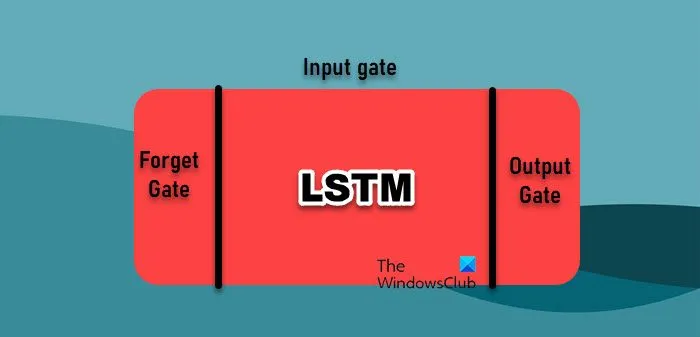
Bij data-analyse vertrouwt time series forecasting op verschillende machine learning-algoritmen, elk met zijn eigen sterke punten. We zullen het echter hebben over twee van de meest gebruikte.
- Long Short-Term Memory Network: Long Short-Term Memory (LSTM)-netwerken zijn een type Recurrent Neural Network (RNN) dat bijzonder effectief is in het leren van sequenties, waardoor ze zeer geschikt zijn voor tijdreeksgegevens. In tegenstelling tot traditionele RNN’s, die worstelen met langetermijnafhankelijkheden vanwege het probleem van de verdwijnende gradiënt, kunnen LSTM’s informatie gedurende lange perioden bewaren. Dit wordt bereikt door hun unieke architectuur, die poorten bevat om de informatiestroom te beheren, waardoor ze ingewikkelde patronen in tijdreeksgegevens kunnen vastleggen.
- Randon Forest: Random Forest is een ensemble learning-methode (hier twee of meer leerlingen). Tijdens de training bouwt het meerdere beslissingsbomen en berekent vervolgens het gemiddelde van hun voorspellingen. Hoewel het oorspronkelijk niet bedoeld is voor tijdreeksen, kan het worden aangepast voor voorspellingen door vertraagde variabelen op te nemen. Random Forest kan veel functies aan en is minder geneigd tot overfit, waardoor het een goede keuze is voor complexe datasets.
U kunt deze twee modellen en enkele andere, zoals VAR, ARIRA en Prophet Models, integreren om het best mogelijke resultaat te bereiken.
Machine Learning-modellen voor aandelenvoorspelling

Aandelen zijn willekeurig, maar tegelijkertijd heeft deze willekeur ook een patroon. Als uw project gericht is op het maken van een aandelenvoorspelling, raden we u aan om een of beide van de hieronder genoemde modellen te gebruiken.
- Beslissingsboom: Een beslissingsboom is een soort stroomdiagram dat helpt bij het nemen van beslissingen of voorspellingen. Het heeft knooppunten voor beslissingen of tests op kenmerken, takken voor de uitkomsten van deze beslissingen en bladknooppunten voor uiteindelijke uitkomsten of voorspellingen. Elk intern knooppunt vertegenwoordigt een test op een kenmerk, elke tak vertegenwoordigt het resultaat van de test en elk bladknooppunt vertegenwoordigt een klasselabel of een continue waarde.
- Neural Network: Neurale netwerken zijn computermodellen die de ingewikkelde functies van het menselijk brein imiteren. Ze bestaan uit onderling verbonden knooppunten of neuronen die data verwerken en ervan leren. Dit maakt taken mogelijk zoals patroonherkenning en besluitvorming in machine learning. Als je ze goed traint, kunnen ze functioneren als meesters van aandelen.
Houd er echter rekening mee dat het lastig kan zijn om standaardpatronen te achterhalen. Vertrouw daarom niet te veel op deze modellen en gebruik liever andere modellen, zoals Randon Forest en LSTM.
Machine Learning-modellen voor multiclass-classificaties
Laten we het nu hebben over een van de meest voorkomende taken van machine learning: multiclass-classificatie. Onze taak is om een model te ontwerpen dat, met behulp van eerdere gegevens, naar een stukje informatie kan kijken en het kan classificeren. Het model analyseert de trainingsdataset om unieke patronen voor elke klasse te vinden. Vervolgens gebruikt het deze patronen om de categorie van toekomstige gegevens te voorspellen. Twee van de meest voorkomende algoritmen en modellen worden hieronder genoemd.
- SVM’s zijn goed in het werken met veel informatie en het vinden van patronen, dus ze zijn nuttig op veel verschillende gebieden. Dankzij al deze faciliteiten die het biedt, kan het worden gebruikt om gegevens te monitoren en te classificeren.
- Het omvat Multinomial Naive Bayes, Bernoulli Naive Bayes en Gaussian Naive Bayes. Naive Bayes-classificatoren zijn een groep classificatiealgoritmen gebaseerd op de stelling van Bayes. Ze zijn niet slechts één algoritme, maar eerder een familie van algoritmen die allemaal hetzelfde principe volgen: elk paar kenmerken dat wordt geclassificeerd, is onafhankelijk van elkaar.
U kunt voor deze functie ook het Neural Network (zie hierboven) gebruiken.
Machine Learning Model voor Regressie

Regressie wordt gebruikt om continue waarde te voorspellen, een van de meest benodigde functies. Daarom zijn er verschillende algoritmes in het spel. De volgende twee zijn degene waarmee u zou moeten beginnen.
- Lineaire regressie: Lineaire regressie is een veelgebruikt algoritme in machine learning. Het omvat het selecteren van een sleutelvariabele uit de dataset om de uitvoervariabelen te voorspellen, zoals toekomstige waarden. Dit algoritme is geschikt voor gevallen met continue labels, zoals het voorspellen van het aantal dagelijkse vluchten vanaf een luchthaven. De weergave van lineaire regressie is y = ax + b.
- Ridge Regression: Ridge Regression is een ander populair ML-algoritme. Het gebruikt de formule y = Xβ + ϵ. In dit geval vertegenwoordigt ‘y’ de N*1-vector van observaties voor de afhankelijke variabele, terwijl ‘X’ de matrix van regressoren is. De regressiecoëfficiënten worden aangeduid met ‘β’, wat een N*1-vector is, en ‘ϵ’ staat voor de vector van fouten.
Er zijn nog andere regressietechnieken die u kunt gebruiken, zoals neurale netwerkregressie, lasso-regressie, willekeurige bosregressie, beslissingsboomregressie, SVM, polynomiale regressie, Gaussische regressie en het KNN-model.
Machine Learning-model voor kleine datasets
Als u met een kleine dataset werkt, zijn er een aantal ML-modellen die u kunt gebruiken.
- Elastic Net: Elastic Net is een techniek die Lasso (L1) en Ridge (L2) regressiemethoden combineert om scenario’s met meerdere gecorreleerde kenmerken te verwerken. Het slaat een balans tussen Lasso’s spaarzaamheid en Ridge’s regularisatie. De reden waarom Elastic Net wordt gebruikt voor kleine datasets is dat het beter is bij het werken met sterk gecorreleerde predictoren. Omdat het zowel L1- als L2-regularisatie combineert, kan het ook voorkomen dat u effectiever overfit in vergelijking met modellen die slechts één vorm van regularisatie gebruiken.
- Single Hidden Neural Network: In het geval van Single Hidden Neural Network is er slechts één invoer- en één uitvoerlaag van het neurale netwerk. De eenvoud maakt het eenvoudiger om data te implementeren en te begrijpen, wat we nodig hebben bij het werken met kleine datasets. Het maakt het ook eenvoudiger om informatie te generaliseren en te interpreteren.
Voor kleine datasets kunnen verschillende andere modellen worden gebruikt, zoals lineaire discriminantanalyse, kwadratische discriminantanalyse en gegeneraliseerde lineaire modellen. Dit zijn enkele van de nuttigste modellen.
Machine Learning-model voor grote datasets
Het verwerken van grote datasets, of big data, biedt de mogelijkheid tot waardevolle inzichten, maar brengt ook unieke uitdagingen met zich mee. U kunt elk van de modellen gebruiken die we eerder hebben besproken, behalve de modellen die zijn genoemd voor de kleine en grote datasets. Het grootste probleem hier is echter het verwerken van zo’n grote hoeveelheid data. De modellen en algoritmen die hier worden genoemd, zijn dus gericht op het verwerken van een enorme hoeveelheid data.
- Batchverwerking: Batchverwerking is een techniek waarbij een grote dataset wordt verdeeld in kleinere datasets (batches of pakketten) en het model stapsgewijs op elke batch wordt getraind. Deze methode helpt overfitting te voorkomen, een veelvoorkomend probleem bij grote datasets, en maakt het trainingsproces beter beheersbaar.
- Distributed Computing: Distributed computing betekent het verspreiden van data en taken over meerdere machines of processors om de training van grote en complexe machine learning-modellen te versnellen. Frameworks zoals Apache Hadoop en Apache Spark bieden sterke platforms voor distributed computing.
Voor grote datasets kunt u ook andere ML-modellen gebruiken, zoals lineaire regressie en neurale netwerken.
Wat is het beste machine learning-model?
Verschillende machine learning-modellen zijn onder andere Naive Bayes, KNN, Random Forest, Boosting, AdaBoot, Linear Regression en meer. Het model dat u kiest, hangt echter af van de situatie of het project waaraan u werkt. We hebben hierboven enkele van de gevallen genoemd en de beste modellen en algoritmen om te gebruiken.
Wat zijn de 4 machine learning-modellen?
De vier machine-learningmodellen zijn het supervised learning-model, unsupervised learning-model, semi-supervised learning-model en reinforcement learning-model. Elk heeft zijn eigen voordelen, dus ze zouden allemaal samen gebruikt moeten worden.


Geef een reactie