
AI dringt uw browser binnen en is sneller dan ooit
We vroegen ons af wanneer ze de volledige kracht van AI in onze browsers zullen gebruiken en blijkbaar is het zover.
We hebben het over een nieuwe functie genaamd ONNX Runtime Web, die gebruikmaakt van de WebGPU-accelerator waarmee AI-modellen rechtstreeks in de browser kunnen worden ingebouwd en sneller kunnen worden gemaakt. Een stuk sneller!
Wat is het ONNX Runtime Web?
Om dat uit te leggen moet je weten dat WebGPU een engine is, net als WebGL, maar dan veel krachtiger en in staat om grotere rekenwerklasten aan te kunnen. Het maakt in feite gebruik van de GPU-kracht om parallelle rekentaken uit te voeren die nodig zijn in AI-processen.
Als we nu naar ONNX Runtime Web gaan: het is een JavaScript-bibliotheek waarmee webontwikkelaars LLM’s rechtstreeks in de webbrowsers kunnen insluiten en kunnen profiteren van de GPU-hardwareversnelling.
Meestal zijn grote LLM’s niet zo gemakkelijk in browsers te implementeren, omdat ze veel geheugen en rekenkracht vereisen.
De innovatie van ONNX Runtime Web is dat het de WebGPU-backend mogelijk maakt die Microsoft en Intel momenteel ontwikkelen.
Hoe snel is het ONNX Runtime Web?
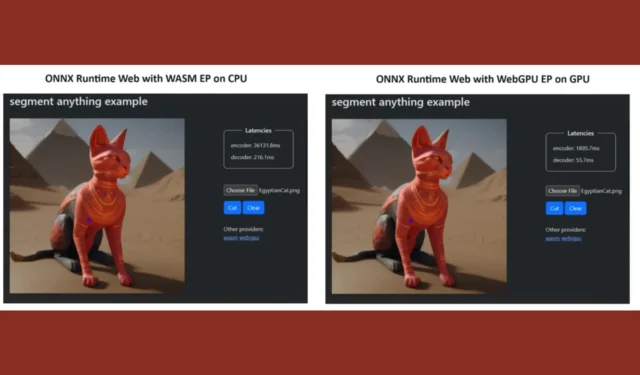
Om hun punt te bewijzen, heeft het ONNX Runtime-team een demo gemaakt met behulp van het Segment Anything-model , en de resultaten waren ronduit verbluffend.
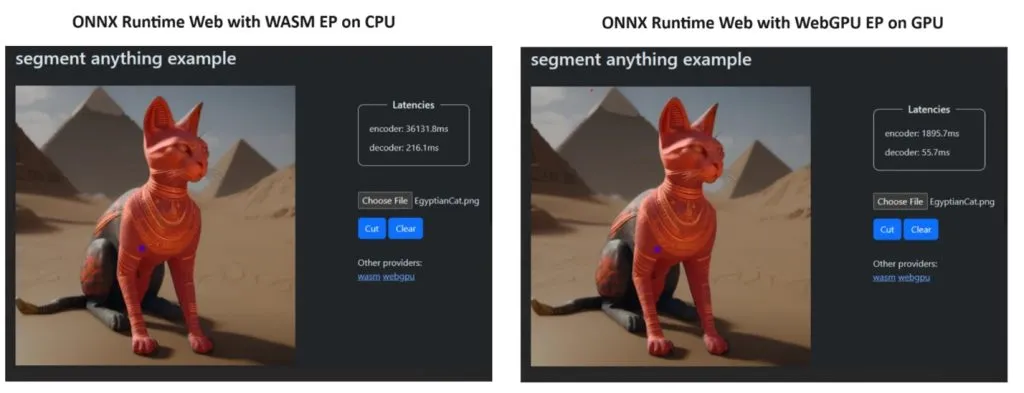
Ze integreerden WASM EP en WebGPU EP en gebruikten een NVIDIA GeForce RTX 3060 en Intel Core i9 pc. Vervolgens vergeleken ze de encoder met behulp van de CPU en de nieuwe WebGPU en deze laatste bleek een stuk sneller te zijn, zoals te zien is in de schermafbeelding hierboven.
Het goede nieuws is dat WebGPU al is ingebed in Chrome 113 en Edge 113 voor Windows, macOS en ChromeOS en Chrome 121 voor Android. Dat betekent dat je ook in deze browsers met ONNX Runtime Web kunt spelen.
De ontwikkelaars hebben op hun projectpagina uitgelegd hoe ze ONNX Runtime Web kunnen proberen:
Dus nu we iets op orde hebben, laten we beginnen met het implementeren van een aantal krachtige LLM’s in de browsers!
Wat vind je van het nieuwe ONNX Runtime Web? Laten we het over deze ontwikkeling hebben in de opmerkingen hieronder.
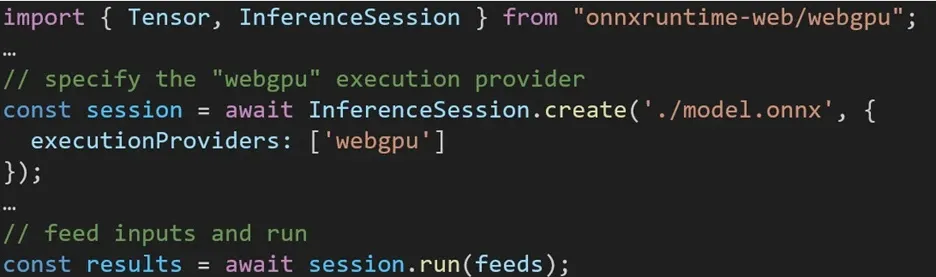
De ervaring met het gebruik van verschillende backends in ONNX Runtime Web is eenvoudig. Importeer eenvoudigweg het relevante pakket en creëer een ONNX Runtime Web-inferentiesessie met de vereiste backend via de Execution Provider-instelling. We streven ernaar het proces voor ontwikkelaars te vereenvoudigen, waardoor ze met minimale inspanning verschillende hardwareversnellingen kunnen benutten.
Het volgende codefragment laat zien hoe u ONNX Runtime Web API kunt aanroepen om een model met WebGPU af te leiden. Aanvullende ONNX Runtime Web-documentatie en voorbeelden zijn beschikbaar om dieper in te gaan.


Geef een reactie