VLOGGER AI: 이제 사진으로 실제와 같은 아바타를 만들고 음성으로 제어하세요.
Google의 연구원들은 AI 기술을 더욱 스마트하게 만들기 위해 매일 노력하고 있습니다. 그들이 진행하고 있는 최신 연구 프로젝트 중 하나는 VLOGGER입니다.
VLOGGER는 다음과 같이 설명됩니다.
GitHub 의 블로그 게시물 에 따르면 이 접근 방식을 사용하면 원하는 길이의 고품질 비디오를 생성할 수 있습니다. 모든 사람을 교육할 필요가 없으므로 얼굴 인식 자르기에 의존하지 않습니다. 완전한 이미지를 생성하고 넓은 스펙트럼을 고려할 수 있으며 이는 의사소통하는 인간을 합성하는 데 중요합니다.
현재 VLOGGER는 개발 중이므로 사용할 수 없지만, 시장에 출시되면 Skype, Teams 또는 Slack에서 화상 회의를 통해 소통할 수 있는 좋은 방법이 될 수 있습니다.
Google은 이 프로젝트에 대해 상당한 확신을 가지고 있으며 다양한 벤치마크를 통해 테스트했습니다. 여기에 내용이 있습니다:
VLOGGER는 어떻게 작동하나요?
VLOGGER는 2단계 파이프라인 역할을 하며 텍스트를 이미지, 비디오, 심지어 3D 모델로 변환하는 확률론적 확산 아키텍처에서 작동하는 프레임워크이며 제어 메커니즘도 추가합니다.
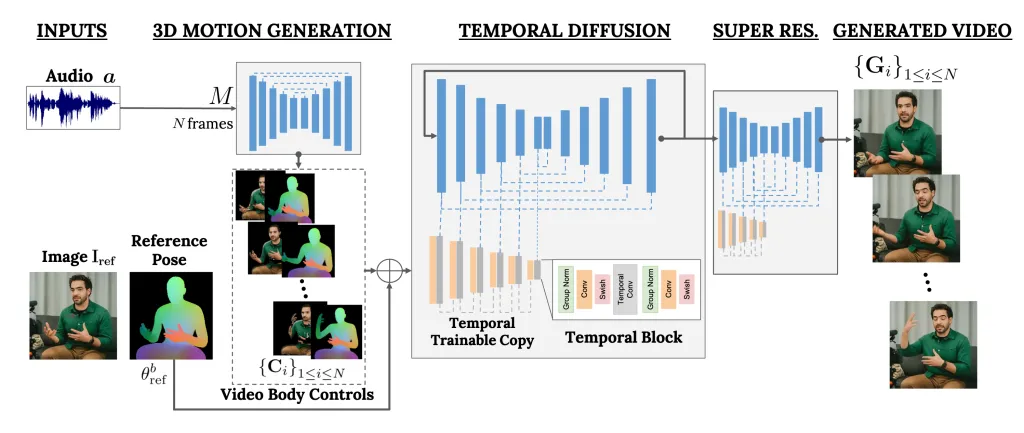
첫 번째 단계는 오디오 파형을 입력으로 사용하여 시선 및 얼굴 표정과 같은 중간 신체 동작 제어를 생성하는 것입니다. 다음으로, 두 번째 네트워크는 시간적 이미지-이미지 변환 모델을 사용하여 이러한 움직임과 사람의 참조 이미지를 식별하여 비디오용 프레임을 생성합니다.
VLOGGER의 또 다른 중요한 기능은 기존 비디오를 편집하는 기능입니다. 영상을 촬영하여 영상 속 인물의 표정을 바꿀 수 있습니다.
게다가 VLOGGER는 비디오 번역에도 도움을 줄 수 있습니다. 특정 언어로 된 기존 비디오를 가져와서 입술과 얼굴 영역을 편집하여 새로운 오디오나 다른 언어와 일관되게 만들 수 있습니다.
VLOGGER는 제품이 아니라 연구 프로젝트이고 완성되지 않았기 때문에 신뢰할 수 없습니다. 예, 사실적인 움직임을 만들 수 있지만 사람이 실제로 움직이는 방식과 일치하지 못할 수도 있습니다. 확산 모델을 고려하면 비정상적인 동작을 보일 수 있습니다.
또한 큰 동작이나 다양한 환경에 능숙하지 않아 짧은 영상에만 작업이 가능하다는 점도 언급했다.
그것이 당신에게 도움이 될 수 있다고 생각하시나요? 아래 댓글 섹션에서 독자들과 의견을 공유하세요.
우리는 세 가지 다른 벤치마크에서 VLOGGER를 평가하고 제안된 모델이 이미지 품질, 정체성 보존 및 시간적 일관성 측면에서 다른 최첨단 방법을 능가한다는 것을 보여줍니다. 우리는 주요 기술 기여를 훈련하고 제거하는 이전 데이터 세트(2,200시간 및 800,000개의 ID, 120시간 및 4,000개의 ID로 구성된 테스트 세트)보다 한 단계 더 큰 새롭고 다양한 데이터 세트 MENTOR를 수집합니다. 우리는 다양한 다양성 지표와 관련하여 VLOGGER의 성능을 보고하며, 아키텍처 선택이 규모에 맞게 공정하고 편견 없는 모델을 교육하는 데 도움이 된다는 것을 보여줍니다.
최근 생성 확산 모델의 성공을 기반으로 한 사람의 단일 입력 이미지에서 텍스트 및 오디오 기반 말하는 인간 비디오 생성 방법입니다.
우리의 방법은 1) 확률론적 인간-3D 모션 확산 모델, 2) 시간적 및 공간적 제어를 모두 사용하여 텍스트-이미지 모델을 강화하는 새로운 확산 기반 아키텍처로 구성됩니다.


답글 남기기