Reddit, Bing 및 기타 검색 엔진의 데이터 스크래핑 차단 – 하지만 Google은 차단하지 않음
알아야 할 사항
- Reddit은 Bing 및 기타 검색 엔진이 사이트를 크롤링하는 것을 방지하기 위해 robots.txt 파일을 업데이트했습니다.
- Reddit은 단속 조치가 검색 엔진과의 합의 실패 및 Reddit 콘텐츠 사용과 관련하여 집행 가능한 약속을 하지 않으려는 회사와의 합의 실패로 인한 것이라고 주장합니다.
- 구글은 Reddit과 6,000만 달러 규모의 계약 덕분에 검색 결과에 Reddit의 최신 콘텐츠를 표시할 수 있는 유일한 주요 검색 엔진이라고 합니다.
Reddit은 웹 크롤러가 데이터를 사용하지 못하도록 하는 노력을 강화하고 있습니다. 단속의 결과로 현재 Bing이든 DuckDuckGo이든 주요 검색 엔진은 검색 결과에 최근 Reddit 게시물과 댓글을 제공할 수 없습니다. Google을 제외하고는 없습니다.
따라서 검색 엔진 쿼리에서 최근 Reddit 결과를 검색하려고 했다면 불행히도 부족할 것입니다. 최근 뉴스 토론에 대한 동일한 쿼리에 대한 Bing과 Google의 검색 결과를 비교해보세요.
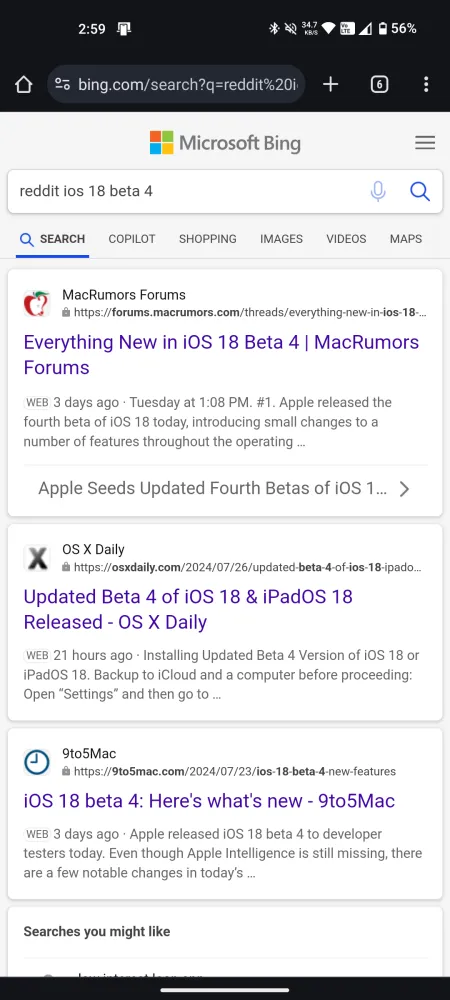
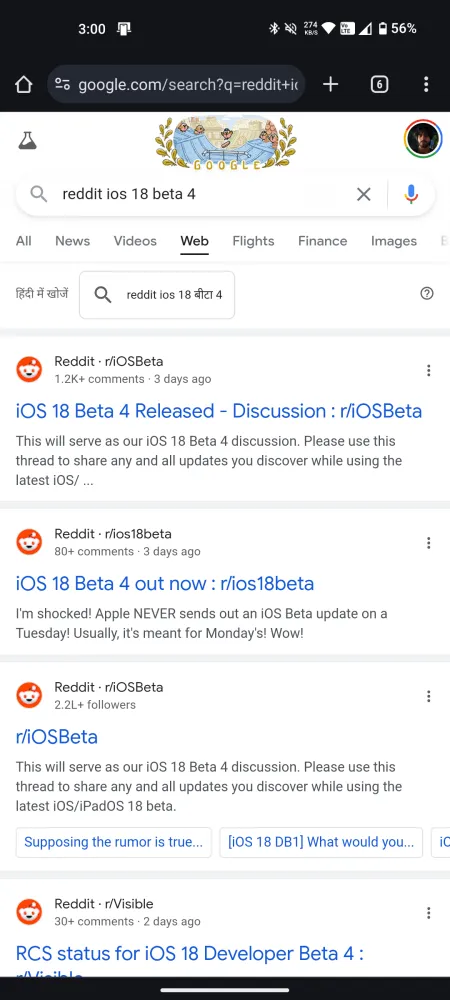
Reddit은 최근 들어 데이터를 점점 더 보호하고 있으며, 이는 이해할 만한 일입니다. 사람들이 모여 관심사에 대해 토론하고 이야기하는 인기 있는 커뮤니티 포럼인 Reddit은 AI 훈련을 위한 진정한 금광입니다. 하지만 Reddit은 AI 회사와 마찬가지로 AI 챗봇이 웹을 장악하고 있는 시기에 이 웹사이트가 얼마나 귀중한 리소스인지 알고 있습니다.
Reddit은 이익을 보호하기 위해 robots.txt 파일을 업데이트 하여 웹 크롤러가 웹사이트에 액세스하지 못하도록 했습니다. 이러한 조치는 Reddit 콘텐츠 사용과 관련하여 여러 검색 엔진과 합의에 도달하려는 시도가 여러 번 실패한 후에 이루어졌습니다. 검색 엔진을 단속하고 데이터 스크래핑을 중단하는 것은 합의가 없는 사람들이 Reddit 콘텐츠에 액세스해서는 안 된다는 명확한 신호입니다.
지금 현재, Reddit 게시물과 댓글을 검색 결과에 표시할 수 있는 유일한 주요 검색 엔진은 Google입니다. 그리고 이는 우연이 아닙니다. Reddit 대변인은 성명에서 “[t]이것은 Google과의 최근 파트너십과 전혀 관련이 없습니다.”라고 언급했지만, Google이 Reddit의 데이터로 AI 모델을 훈련할 수 있도록 허용한 6,000만 달러 규모의 거래를 간과하기란 쉽지 않습니다. 아마도 이 거래에는 Reddit 콘텐츠에 대한 실시간 액세스도 포함되었을 것입니다.
Reddit의 메시지는 충분히 명확합니다. 지불하거나 놓치세요. Microsoft를 포함한 대부분 회사가 인정했습니다. Microsoft는 성명에서 다음과 같이 말했습니다.
“우리는 robots.txt 표준을 존중합니다. Bing은 7월 1일에 업데이트된 robots.txt 파일을 구현한 후 Reddit 크롤링을 중단했습니다. 이 파일은 모든 사이트 크롤링을 금지합니다.”
Google이 아닌 검색 엔진을 사용하는 사람들은 분명히 불리한 입장에 처해 있는데, 주로 Reddit 자체의 검색 기능이 관련 콘텐츠를 찾는 데 검색 엔진만큼 잘 작동하지 않기 때문입니다. 현재로서는 “site:reddit.com” 트릭을 사용하거나 쿼리에 ‘Reddit’이라는 단어를 추가하여 Reddit에서 최근 결과를 얻으려면 먼저 Google을 열어야 합니다.


답글 남기기