AI가 브라우저에 들어가 그 어느 때보다 빨라졌습니다.
우리는 브라우저 내에서 AI의 모든 기능을 언제 사용할지 궁금했고, 분명히 때가 왔습니다.
우리는 AI 모델을 브라우저에 직접 구축하고 더 빠르게 만들 수 있는 WebGPU 가속기를 사용하는 ONNX Runtime Web이라는 새로운 기능에 대해 이야기하고 있습니다. 훨씬 더 빨라요!
ONNX 런타임 웹이란 무엇입니까?
이를 설명하려면 WebGPU가 WebGL과 같은 엔진이지만 훨씬 더 강력하고 대규모 계산 작업 부하를 처리할 수 있다는 점을 알아야 합니다. 기본적으로 GPU 성능을 활용하여 AI 프로세스에 필요한 병렬 계산 작업을 수행합니다.
이제 ONNX Runtime Web으로 이동하면 웹 개발자가 LLM을 웹 브라우저에 바로 내장하고 GPU 하드웨어 가속의 이점을 누릴 수 있게 해주는 JavaScript 라이브러리입니다.
일반적으로 대규모 LLM은 많은 메모리와 계산 능력이 필요하기 때문에 브라우저에 쉽게 배포되지 않습니다.
ONNX Runtime Web의 혁신은 Microsoft와 Intel이 현재 개발 중인 WebGPU 백엔드를 가능하게 한다는 것입니다.
ONNX 런타임 웹은 얼마나 빠른가요?
그들의 주장을 입증하기 위해 ONNX Runtime 팀은 Segment Anything 모델을 사용하여 데모를 만들었고 그 결과는 거의 놀라웠습니다.
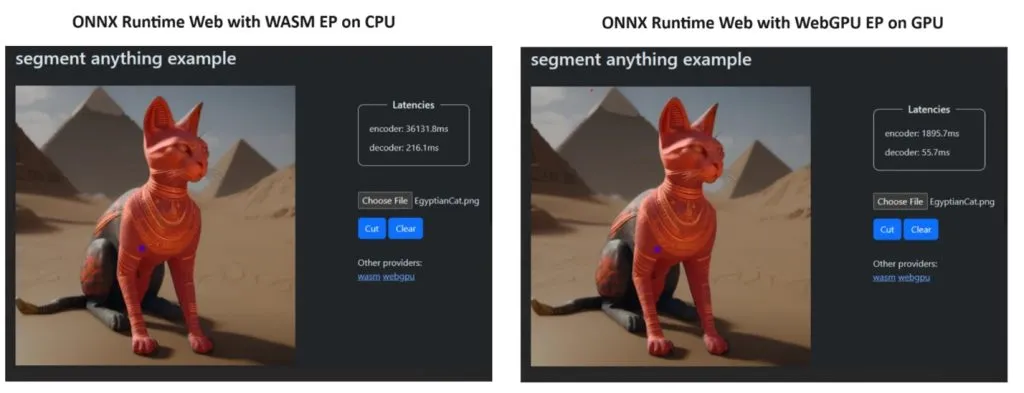
WASM EP와 WebGPU EP를 통합하고 NVIDIA GeForce RTX 3060 및 Intel Core i9 PC를 사용했습니다. 그런 다음 CPU를 사용한 인코더와 새로운 WebGPU를 비교한 결과 위 스크린샷에서 볼 수 있듯이 후자가 훨씬 빠른 것으로 나타났습니다.
좋은 소식은 WebGPU가 Windows, macOS, ChromeOS용 Chrome 113 및 Edge 113과 Android용 Chrome 121에 이미 내장되어 있다는 것입니다. 즉, 이러한 브라우저에서 ONNX Runtime Web을 사용할 수도 있습니다.
개발자는 프로젝트 페이지에서 ONNX Runtime Web을 사용해 보는 방법을 설명했습니다.
이제 모든 것이 준비되었으므로 강력한 LLM을 브라우저에 배포해 보겠습니다!
새로운 ONNX 런타임 웹에 대해 어떻게 생각하시나요? 아래 댓글 섹션에서 이 개발에 대해 이야기해 보겠습니다.
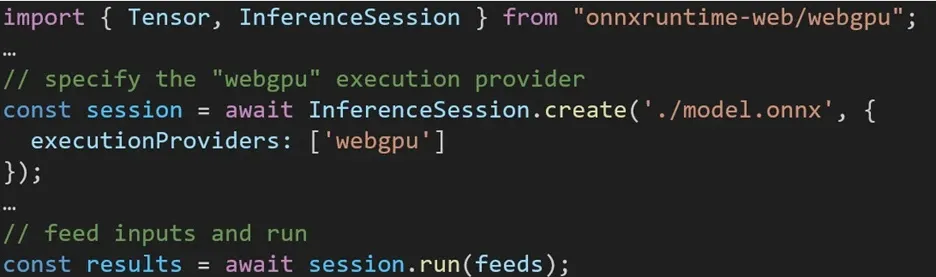
ONNX Runtime Web에서 다양한 백엔드를 활용하는 경험은 간단합니다. 관련 패키지를 가져오고 실행 공급자 설정을 통해 필요한 백엔드로 ONNX 런타임 웹 추론 세션을 생성하기만 하면 됩니다. 우리는 개발자가 최소한의 노력으로 다양한 하드웨어 가속을 활용할 수 있도록 프로세스를 단순화하는 것을 목표로 합니다.
다음 코드 조각은 ONNX Runtime Web API를 호출하여 WebGPU로 모델을 추론하는 방법을 보여줍니다. 더 자세히 알아보려면 추가 ONNX 런타임 웹 문서 및 예제 에 액세스할 수 있습니다.


답글 남기기