
VLOGGER AI: ora crea un avatar realistico da una foto e usa la tua voce per controllarlo
I ricercatori di Google lavorano ogni giorno per rendere la sua tecnologia AI più intelligente. Uno degli ultimi progetti di ricerca su cui stanno lavorando è VLOGGER.
VLOGGER è spiegato come
Secondo il post sul blog su GitHub, questo approccio consente la generazione di video di alta qualità e di lunghezza desiderabile. Senza la necessità di formazione per ogni persona, non dipende dal ritaglio del rilevamento dei volti; può generare l’immagine completa e tenere conto di un ampio spettro, il che è importante per sintetizzare gli esseri umani che comunicano.
Al momento, VLOGGER non è disponibile per l’uso poiché è ancora in fase di sviluppo, ma quando arriverà sul mercato, potrebbe essere un ottimo modo per comunicare in videoconferenza su Skype, Teams o Slack.
Google è abbastanza fiduciosa nel progetto e lo ha testato attraverso vari benchmark; ecco cosa dice:
Come funziona VLOGGER?
VLOGGER è un framework che funge da pipeline a due stadi e funziona su un’architettura di diffusione stocastica che alimenta il testo in immagini, video e persino modelli 3D, ma aggiunge anche un meccanismo di controllo.
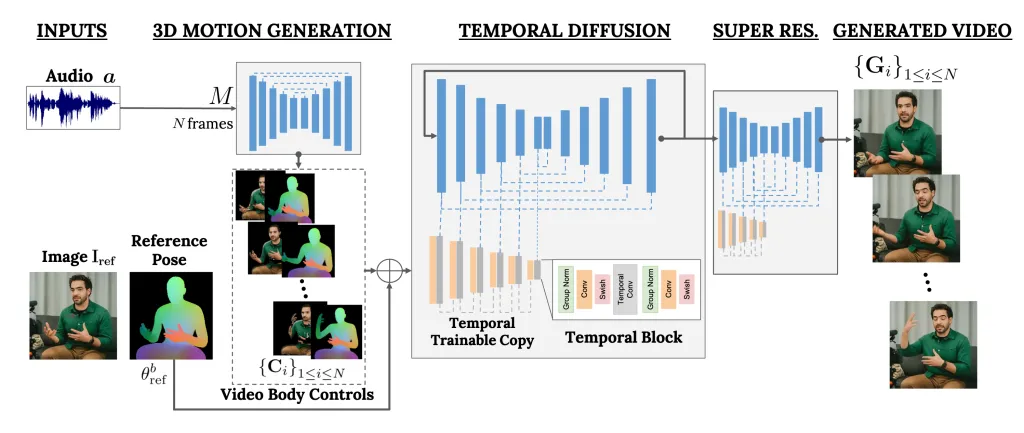
Il primo passo è prendere una forma d’onda audio come input per generare controlli intermedi del movimento del corpo come lo sguardo e le espressioni facciali. Successivamente, la seconda rete utilizza un modello di traduzione temporale da immagine a immagine per identificare questi movimenti e un’immagine di riferimento di una persona per generare fotogrammi per il video.
Un’altra caratteristica importante di VLOGGER è la possibilità di modificare i video esistenti. Può prendere un video e cambiare l’espressione della persona nel video.
Inoltre, il VLOGGER può anche aiutare nella traduzione dei video; può prendere un video esistente in una lingua specifica e modificare l’area delle labbra e del viso per renderlo coerente con il nuovo audio o con lingue diverse.
Poiché VLOGGER non è un prodotto ma un progetto di ricerca e non è completo, non si può fare affidamento su di esso. Sì, può creare movimenti realistici, ma potrebbe non essere in grado di riprodurre il modo in cui una persona si muove realmente. Dato il suo modello di diffusione, potrebbe mostrare comportamenti insoliti.
Il suo team ha anche affermato che non è esperto in grandi movimenti o ambienti diversi e può lavorare solo per brevi video.
Pensi che potrebbe esserti utile? Condividi le tue opinioni con i nostri lettori nella sezione commenti qui sotto
Valutiamo VLOGGER su tre diversi parametri di riferimento e mostriamo che il modello proposto supera altri metodi all’avanguardia in termini di qualità dell’immagine, conservazione dell’identità e coerenza temporale. Raccogliamo un nuovo e diversificato set di dati MENTOR un ordine di grandezza più grande di quelli precedenti (2.200 ore e 800.000 identità e un set di test di 120 ore e 4.000 identità) su cui addestriamo e ablamo i nostri principali contributi tecnici. Riportiamo le prestazioni di VLOGGER rispetto a molteplici parametri di diversità, dimostrando che le nostre scelte architetturali vanno a vantaggio della formazione di un modello giusto e imparziale su larga scala.
Un metodo per la generazione di video umani parlanti basati su testo e audio da una singola immagine di input di una persona, che si basa sul successo dei recenti modelli di diffusione generativa.
Il nostro metodo consiste in 1) un modello stocastico di diffusione uomo-movimento 3D e 2) una nuova architettura basata sulla diffusione che aumenta i modelli testo-immagine con controlli sia temporali che spaziali.


Lascia un commento