
I migliori modelli di apprendimento automatico da conoscere
Se vuoi sfruttare la potenza dell’intelligenza artificiale e dell’apprendimento automatico, devi conoscere alcuni dei migliori modelli di apprendimento automatico. Esistono dozzine di modelli di apprendimento automatico, quindi può essere un po’ confusionario scegliere modelli di apprendimento automatico per un progetto. In questo post parleremo di alcuni dei migliori modelli di apprendimento automatico che puoi utilizzare a seconda del tuo progetto.
I migliori modelli di apprendimento automatico da conoscere
Disponiamo dell’elenco dei modelli e degli algoritmi di apprendimento automatico per i seguenti progetti, istanze e scenari.
Modelli di apprendimento automatico per la previsione delle serie temporali
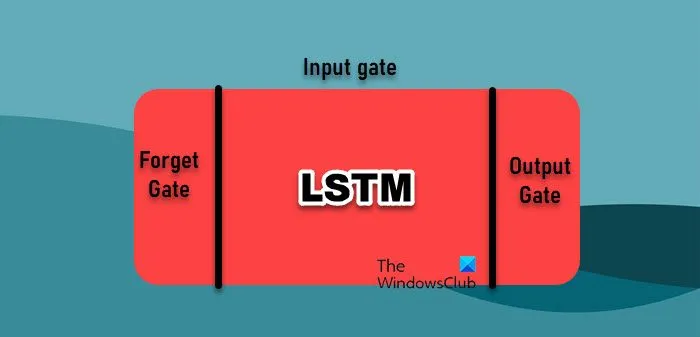
Nell’analisi dei dati, la previsione delle serie temporali si basa su vari algoritmi di apprendimento automatico, ognuno con i suoi punti di forza. Tuttavia, parleremo di due dei più utilizzati.
- Long Short-Term Memory Network: le reti Long Short-Term Memory (LSTM) sono un tipo di Recurrent Neural Network (RNN) particolarmente efficaci nell’apprendimento dalle sequenze, il che le rende adatte ai dati delle serie temporali. A differenza delle RNN tradizionali, che hanno difficoltà con le dipendenze a lungo termine a causa del problema del gradiente evanescente, le LSTM possono conservare le informazioni per lunghi periodi. Ciò è possibile grazie alla loro architettura unica, che include gate per gestire il flusso di informazioni, consentendo loro di catturare modelli intricati nei dati delle serie temporali.
- Randon Forest: Random Forest è un metodo di apprendimento d’insieme (qui due o più studenti). Durante l’addestramento, crea più alberi decisionali e quindi calcola la media delle loro previsioni. Sebbene non sia stato originariamente pensato per le serie temporali, può essere adattato per le previsioni includendo variabili ritardate. Random Forest può gestire molte funzionalità ed è meno probabile che si adatti eccessivamente, il che lo rende una scelta forte per set di dati complessi.
È possibile integrare questi due modelli e alcuni altri, come VAR, ARIRA e Prophet Models, per ottenere il miglior risultato possibile.
Modelli di apprendimento automatico per la previsione delle azioni

Le azioni sono casuali, ma allo stesso tempo questa casualità ha anche uno schema. Se il tuo progetto mira a fare una previsione sulle azioni, ti consigliamo di usare uno o entrambi i modelli menzionati di seguito.
- Albero decisionale: un albero decisionale è un tipo di diagramma di flusso che aiuta a prendere decisioni o previsioni. Ha nodi per decisioni o test su attributi, rami per i risultati di queste decisioni e nodi foglia per i risultati finali o le previsioni. Ogni nodo interno rappresenta un test su un attributo, ogni ramo rappresenta il risultato del test e ogni nodo foglia rappresenta un’etichetta di classe o un valore continuo.
- Reti neurali: le reti neurali sono modelli di computer che imitano le complesse funzioni del cervello umano. Sono costituite da nodi o neuroni interconnessi che elaborano e apprendono dai dati. Ciò consente attività come il riconoscimento di pattern e il processo decisionale nell’apprendimento automatico. Se le si addestra bene, possono funzionare come maestri di azioni.
Tuttavia, è necessario ricordare che individuare gli andamenti azionari può essere molto complicato, quindi non bisogna fare troppo affidamento su questi modelli, ma incorporarne altri, come Randon Forest e LSTM.
Modelli di apprendimento automatico per classificazioni multiclasse
Ora, parliamo di uno dei lavori di apprendimento automatico più comuni: la classificazione multiclasse. Qui, il nostro lavoro è quello di elaborare un modello che, con l’aiuto dei dati precedenti, possa esaminare un’informazione e classificarla. Il modello analizza il set di dati di training per trovare pattern univoci per ogni classe. Quindi utilizza questi pattern per prevedere la categoria dei dati futuri. Di seguito sono menzionati due degli algoritmi e modelli più comuni.
- Gli SVM sono bravi a lavorare con molte informazioni e a trovare pattern, quindi sono utili in molte aree diverse. In virtù di tutte queste strutture che forniscono, possono essere usati per monitorare i dati e classificarli.
- Include Multinomial Naive Bayes, Bernoulli Naive Bayes e Gaussian Naive Bayes. I classificatori Naive Bayes sono un gruppo di algoritmi di classificazione basati sul teorema di Bayes. Non sono solo un algoritmo, ma piuttosto una famiglia di algoritmi che seguono tutti lo stesso principio: ogni coppia di caratteristiche classificate è indipendente l’una dall’altra.
Per questa funzionalità è possibile utilizzare anche la rete neurale (i cui dettagli sono indicati sopra).
Modello di apprendimento automatico per la regressione

La regressione è usata per prevedere il valore continuo, una delle caratteristiche più necessarie. Ecco perché ci sono vari algoritmi in gioco qui. I due seguenti sono quelli con cui dovresti iniziare.
- Regressione lineare: la regressione lineare è un algoritmo ampiamente utilizzato nell’apprendimento automatico. Comporta la selezione di una variabile chiave dal set di dati per prevedere le variabili di output, come i valori futuri. Questo algoritmo è adatto per casi con etichette continue, come la previsione del numero di voli giornalieri da un aeroporto. La rappresentazione della regressione lineare è y = ax + b.
- Ridge Regression: Ridge Regression è un altro algoritmo ML popolare. Utilizza la formula y = Xβ + ϵ. In questo caso, ‘y’ rappresenta il vettore N*1 di osservazioni per la variabile dipendente, mentre ‘X’ è la matrice dei regressori. I coefficienti di regressione sono indicati da ‘β’, che è un vettore N*1, e ‘ϵ’ sta per il vettore degli errori.
Esistono altre tecniche di regressione che è possibile utilizzare, come la regressione delle reti neurali, la regressione Lasso, la Random Forest, la regressione degli alberi decisionali, la SVM, la regressione polinomiale, la regressione gaussiana e il modello KNN.
Modello di apprendimento automatico per piccoli set di dati
Se si ha a che fare con un set di dati di piccole dimensioni, ci sono alcuni modelli di ML che è possibile utilizzare.
- Elastic Net: Elastic Net è una tecnica che combina i metodi di regressione Lasso (L1) e Ridge (L2) per gestire scenari con più feature correlate. Raggiunge un equilibrio tra la scarsità di Lasso e la regolarizzazione di Ridge. Il motivo per cui Elastic Net viene utilizzato per piccoli set di dati è che è migliore quando si ha a che fare con predittori altamente correlati. Inoltre, poiché combina sia la regolarizzazione L1 che L2, può impedire l’overfitting in modo più efficace rispetto ai modelli che utilizzano solo una forma di regolarizzazione.
- Single Hidden Neural Network: nel caso di Single Hidden Neural Network, c’è solo un livello di rete neurale di input e uno di output. La semplicità rende più facile implementare e comprendere i dati, che è ciò di cui abbiamo bisogno quando si ha a che fare con piccoli set di dati. Inoltre, rende più facile generalizzare e interpretare le informazioni.
Per piccoli set di dati possono essere utilizzati vari altri modelli, come l’analisi discriminante lineare, l’analisi discriminante quadratica e il modello lineare generalizzato, che sono tra i più utili.
Modello di apprendimento automatico per grandi set di dati
L’elaborazione di grandi set di dati, o big data, ha il potenziale per approfondimenti preziosi, ma pone sfide uniche. Puoi usare uno qualsiasi dei modelli di cui abbiamo parlato in precedenza, esclusi quelli menzionati per i set di dati piccoli e grandi. Tuttavia, il problema più grande qui è l’elaborazione di una così grande quantità di dati. Quindi, i modelli e gli algoritmi menzionati qui mirano a elaborare un’enorme quantità di dati.
- Elaborazione batch: l’elaborazione batch è una tecnica in cui un set di dati di grandi dimensioni viene suddiviso in set di dati più piccoli (batch o pacchetti) e il modello viene addestrato su ogni batch in modo incrementale. Questo metodo aiuta a prevenire l’overfitting, un problema comune con i set di dati di grandi dimensioni, e rende il processo di addestramento più gestibile.
- Elaborazione distribuita: l’elaborazione distribuita significa distribuire dati e attività su più macchine o processori per accelerare l’addestramento di modelli di apprendimento automatico grandi e complessi. Framework come Apache Hadoop e Apache Spark forniscono piattaforme solide per l’elaborazione distribuita.
Per set di dati di grandi dimensioni è possibile utilizzare anche altri modelli di ML, come la regressione lineare e le reti neurali.
Qual è il miglior modello di apprendimento automatico?
Vari modelli di apprendimento automatico includono Naive Bayes, KNN, Random Forest, Boosting, AdaBoot, Linear Regression e altro. Tuttavia, il modello che devi scegliere dipende dalla situazione o dal progetto su cui stai lavorando. Abbiamo menzionato alcuni dei casi sopra e i migliori modelli e algoritmi da utilizzare.
Quali sono i 4 modelli di apprendimento automatico?
I quattro modelli di apprendimento automatico sono il modello di apprendimento supervisionato, il modello di apprendimento non supervisionato, il modello di apprendimento semi-supervisionato e il modello di apprendimento per rinforzo. Ognuno ha i suoi vantaggi, quindi dovrebbero essere usati tutti insieme.


Lascia un commento