L’intelligenza artificiale entra nel tuo browser ed è più veloce che mai
Ci chiedevamo quando sfrutteremo tutta la potenza dell’intelligenza artificiale all’interno dei nostri browser e, a quanto pare, è giunto il momento.
Stiamo parlando di una nuova funzionalità chiamata ONNX Runtime Web che utilizza l’acceleratore WebGPU che consente di incorporare modelli AI direttamente nel browser e renderli più veloci. Molto più veloce!
Cos’è ONNX Runtime Web?
Per spiegarlo, devi sapere che WebGPU è un motore, come WebGL, ma molto più potente, in grado di gestire carichi di lavoro computazionali più grandi. Fondamentalmente sfrutta la potenza della GPU per eseguire attività computazionali parallele necessarie nei processi di intelligenza artificiale.
Ora, arrivando a ONNX Runtime Web, si tratta di una libreria JavaScript che consente agli sviluppatori Web di incorporare LLM direttamente nei browser Web e beneficiare dell’accelerazione hardware della GPU.
Di solito, i LLM di grandi dimensioni non vengono implementati così facilmente nei browser perché richiedono molta memoria e potenza di calcolo.
L’innovazione di ONNX Runtime Web è che abilita il backend WebGPU che Microsoft e Intel stanno sviluppando proprio ora.
Quanto è veloce ONNX Runtime Web?
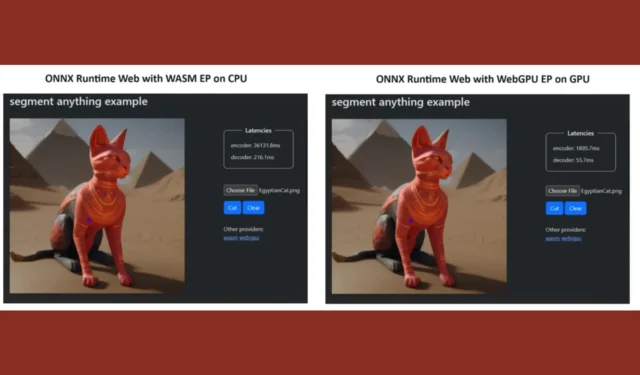
Per dimostrare il proprio punto, il team ONNX Runtime ha creato una demo utilizzando il modello Segment Anything e i risultati sono stati poco meno che sorprendenti.
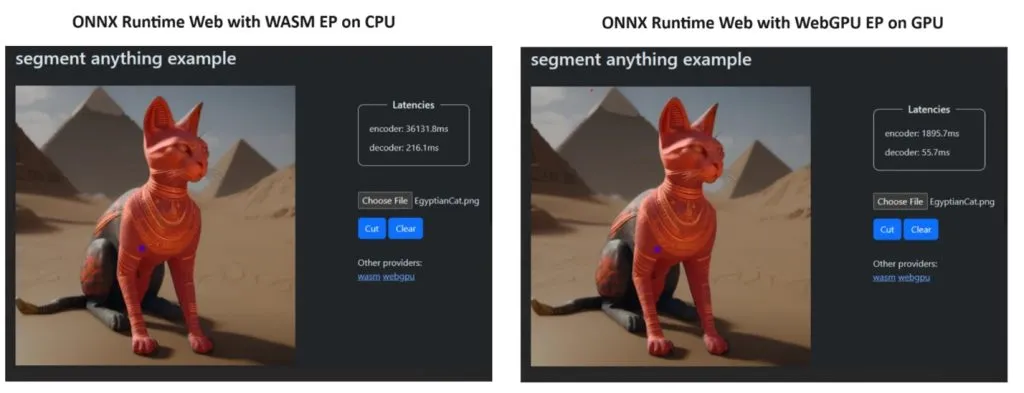
Hanno incorporato WASM EP e WebGPU EP e hanno utilizzato un PC NVIDIA GeForce RTX 3060 e Intel Core i9. Quindi, hanno confrontato l’encoder utilizzando la CPU e la nuova WebGPU e quest’ultima si è rivelata molto più veloce, come mostrato nello screenshot qui sopra.
La buona notizia è che WebGPU è già incorporata in Chrome 113 e Edge 113 per Windows, macOS e ChromeOS e Chrome 121 per Android. Ciò significa che puoi anche giocare con ONNX Runtime Web su questi browser.
Gli sviluppatori hanno spiegato come provare ONNX Runtime Web nella pagina del loro progetto:
Quindi, ora che abbiamo tutto a posto, iniziamo a distribuire alcuni potenti LLM nei browser!
Cosa ne pensi del nuovo ONNX Runtime Web? Parliamo di questo sviluppo nella sezione commenti qui sotto.
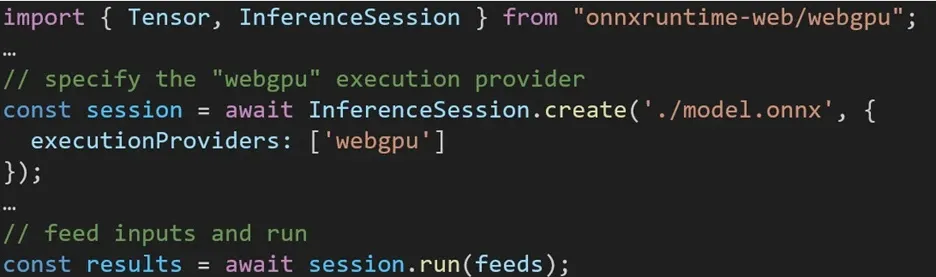
L’esperienza di utilizzo di diversi backend in ONNX Runtime Web è semplice. È sufficiente importare il pacchetto pertinente e creare una sessione di inferenza Web ONNX Runtime con il backend richiesto tramite l’impostazione Execution Provider. Il nostro obiettivo è semplificare il processo per gli sviluppatori, consentendo loro di sfruttare diverse accelerazioni hardware con il minimo sforzo.
Il frammento di codice seguente mostra come chiamare l’API Web ONNX Runtime per dedurre un modello con WebGPU. Ulteriori esempi e documentazione Web di ONNX Runtime sono accessibili per approfondire il problema.
Lascia un commento