
Scopri la nuova funzionalità di Chrome: rendi i PDF scansionati ricercabili e modificabili per un accesso al testo senza sforzo
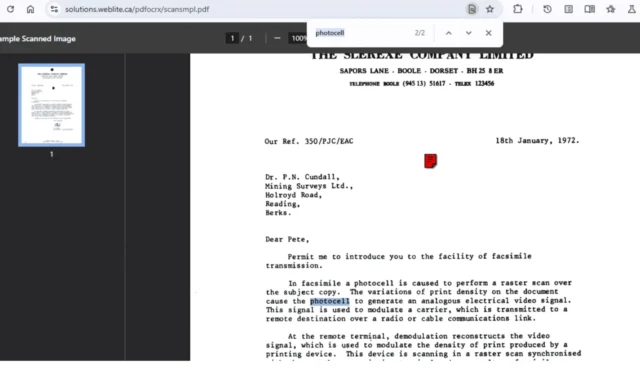
Google sta sperimentando una nuova funzionalità di riconoscimento ottico dei caratteri (OCR) all’interno del visualizzatore PDF integrato di Chrome, progettata per semplificare il processo di estrazione e copia del testo dai documenti PDF scansionati.
Se in passato hai avuto difficoltà a recuperare testo da un PDF scansionato, potresti aver pensato di investire in costosi strumenti OCR o di utilizzare vari servizi online. Tuttavia, non c’è motivo di preoccuparsi! Chrome, un browser che probabilmente utilizzi su dispositivi Windows, Mac, Linux e Chromebook, sta incorporando funzionalità OCR avanzate integrate.
Miglioramenti nell’OCR di Chrome per la visualizzazione di PDF
Attualmente, Chrome sta sperimentando una funzionalità per il suo visualizzatore PDF, nota come “PDF Searchify”, accessibile tramite un flag del browser, che migliora la capacità di individuare e replicare il testo dai PDF scansionati.
Precedentemente disponibili in ChromeOS, le capacità di estrazione del testo ora si rivolgono specificamente alle immagini PDF dagli scanner, consentendo agli utenti di interagire con il testo incorporato in queste immagini. Il Chrome PDF Viewer aggiornato consente la ricerca e la modifica del testo presente nelle immagini PDF, migliorando così l’usabilità e l’accessibilità complessiva.
La “funzione PDF Searchify” applica la tecnologia OCR per riconoscere il testo dalle immagini PDF, rendendolo sia ricercabile che modificabile, ed è operativa su Chrome per Mac, Windows, Linux e ChromeOS.
Per attivare questa funzionalità in Chrome, segui questi passaggi:
- Apri Chrome.
- Vai chrome://flagsa .
- Cercare ” Rendi interattivo il testo nelle immagini PDF “.
- Impostalo su “Abilitato” e riavvia il browser.

Google Chrome fornisce già funzionalità di estrazione del testo tramite Google Lens integrato, che può tradurre ed estrarre testo da vari media, inclusi PDF scansionati. Tuttavia, Google Lens non supporta ancora la ricerca di parole specifiche all’interno di immagini PDF o la modifica del testo estratto.
Questa nuova funzionalità potrebbe presto raggiungere una versione stabile in Chrome. Cosa ne pensi? Sei impressionato dai progressi dell’OCR in Chrome? Condividi le tue opinioni nella sezione commenti qui sotto.
Inoltre, Google Chrome potrebbe presto lanciare un Task Manager rinnovato e abilitare il supporto per estensioni senza ambito all’interno di Omnibox, consentendo a queste estensioni autorizzazioni avanzate per interagire con gli input della barra degli indirizzi.


Lascia un commento