VLOGGER AI : créez maintenant un avatar réaliste à partir d’une photo et utilisez votre voix pour le contrôler
Les chercheurs de Google s’efforcent chaque jour de rendre sa technologie d’IA plus intelligente. L’un des derniers projets de recherche sur lesquels ils travaillent est VLOGGER.
VLOGGER est expliqué comme
Selon le billet de blog sur GitHub, cette approche permet de générer des vidéos de haute qualité et d’une durée souhaitable. Sans la nécessité d’une formation pour chaque personne, cela ne dépend pas du recadrage par détection des visages ; il peut générer l’image complète et prendre en compte un large spectre, ce qui est important pour synthétiser les humains qui communiquent.
Pour l’instant, VLOGGER n’est pas disponible car il est encore en cours de développement, mais lorsqu’il arrivera sur le marché, il pourrait être un excellent moyen de communiquer lors d’une vidéoconférence sur Skype, Teams ou Slack.
Google est assez confiant dans le projet et l’a testé à travers divers benchmarks ; voici ce qu’il dit :
Comment fonctionne VLOGGER ?
VLOGGER est un framework qui agit comme un pipeline en deux étapes et fonctionne sur une architecture de diffusion stochastique qui alimente le texte en image, vidéo et même en modèles 3D, mais ajoute également un mécanisme de contrôle.
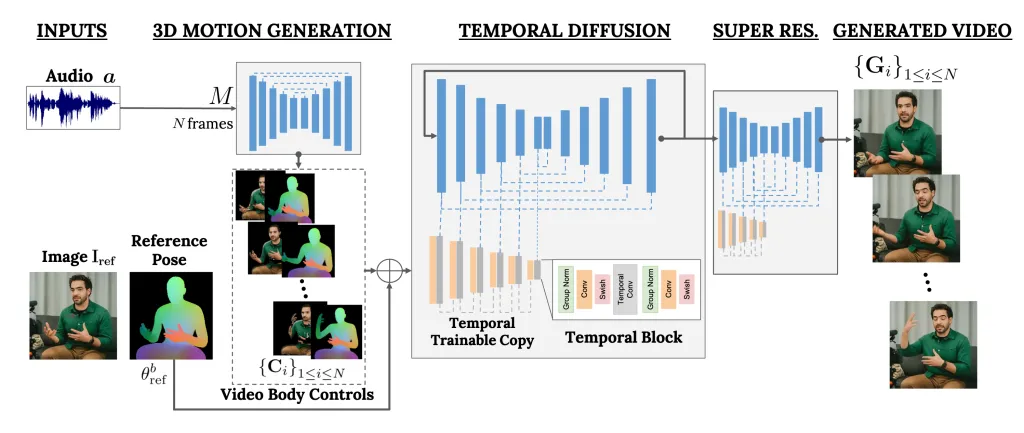
La première étape consiste à prendre une forme d’onde audio comme entrée pour générer des commandes intermédiaires de mouvement du corps comme le regard et les expressions faciales. Ensuite, le deuxième réseau utilise un modèle de traduction temporelle d’image à image pour identifier ces mouvements et une image de référence d’une personne pour générer des images pour la vidéo.
Une autre fonctionnalité importante de VLOGGER est la possibilité d’éditer des vidéos existantes. Il peut prendre une vidéo et changer l’expression de la personne dans la vidéo.
De plus, le VLOGGER peut également aider à la traduction vidéo ; il peut prendre une vidéo existante dans une langue spécifique et modifier la zone des lèvres et du visage pour la rendre cohérente avec le nouvel audio ou différentes langues.
Comme VLOGGER n’est pas un produit mais un projet de recherche et n’est pas complet, on ne peut pas s’y fier. Oui, cela peut créer un mouvement réaliste, mais il peut ne pas correspondre à la façon dont une personne bouge réellement. Compte tenu de son modèle de diffusion, il pourrait présenter un comportement inhabituel.
Son équipe a également mentionné qu’elle n’est pas familiarisée avec les grands mouvements ou les environnements diversifiés et ne peut travailler que sur de courtes vidéos.
Pensez-vous que cela pourrait vous être utile ? Partagez vos opinions avec nos lecteurs dans la section commentaires ci-dessous
Nous évaluons VLOGGER sur trois critères différents et montrons que le modèle proposé surpasse les autres méthodes de pointe en termes de qualité d’image, de préservation de l’identité et de cohérence temporelle. Nous collectons un nouvel ensemble de données diversifié MENTOR d’un ordre de grandeur plus grand que les précédents (2 200 heures et 800 000 identités, et un ensemble de tests de 120 heures et 4 000 identités) sur lequel nous formons et supprimons nos principales contributions techniques. Nous rapportons les performances de VLOGGER par rapport à plusieurs mesures de diversité, montrant que nos choix architecturaux profitent à la formation d’un modèle juste et impartial à grande échelle.
L’invention concerne une méthode de génération de vidéo humaine parlante basée sur du texte et de l’audio à partir d’une seule image d’entrée d’une personne, qui s’appuie sur le succès des récents modèles de diffusion générative.
Notre méthode consiste en 1) un modèle de diffusion stochastique de l’homme vers le mouvement 3D, et 2) une nouvelle architecture basée sur la diffusion qui augmente les modèles texte-image avec des contrôles temporels et spatiaux.
Laisser un commentaire