
Les meilleures alternatives open source à Crawl4AI : comparaison des meilleures options
Crawl4AI est un outil complémentaire pour l’exploration Web et l’extraction de données, répondant notamment aux exigences des grands modèles linguistiques (LLM) et de nombreuses applications basées sur l’IA. Néanmoins, il n’est pas le seul concurrent dans ce domaine. Dans cet article, nous explorerons les meilleures alternatives open source à Crawl4AI .
Les principales alternatives Open Source à Crawl4AI
Vous trouverez ci-dessous quelques alternatives open source notables à Crawl4AI.
- Scrapy
- Colley
- PySpider
- X-Crawl
- Feu de camp
1] Débris

Scrapy se distingue comme un framework open source basé sur Python conçu pour le scraping et l’exploration Web. Il permet aux utilisateurs d’extraire efficacement des données à partir de pages Web. Grâce à son utilisation de Twisted, un framework de réseau asynchrone, Scrapy améliore les performances et la vitesse de traitement.
Ce framework prend en charge l’ajout de middleware et de pipelines, permettant un traitement de données personnalisé. Scrapy est capable de gérer les requêtes, de tracer les liens et d’extraire des informations à l’aide de sélecteurs CSS et XPath, s’intégrant parfaitement à votre environnement actuel.
De plus, Scrapy propose une interface conviviale, simplifiant le processus de suivi et d’extraction de données à partir de divers sites Web. La plateforme s’appuie sur une communauté dynamique et une documentation complète.
Pour installer Scrapy , assurez-vous que vous utilisez Python 3.8 ou une version supérieure (CPython est la valeur par défaut, mais PyPy est également pris en charge). Si vous utilisez Anaconda ou Miniconda, installez le package via le canal conda-forge avec la commande suivante :
conda install -c conda-forge scrapy
Alternativement, pour ceux qui préfèrent PyPI, exécutez la commande dans une invite de commande élevée :
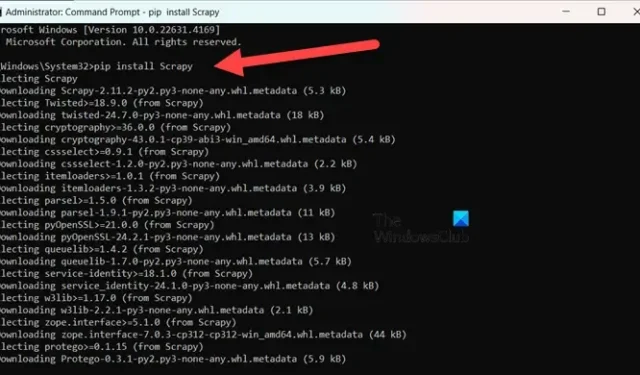
pip install Scrapy
Pour approfondir cet outil, visitez scrapy.org .
2] Colley
Colly est une bibliothèque de scraping simple développée pour Golang. Elle simplifie le processus d’envoi de requêtes HTTP, d’analyse HTML et de récupération de données à partir de sites Web. Colly propose des fonctions qui permettent aux développeurs de naviguer dans les pages Web, de filtrer les éléments à l’aide de sélecteurs CSS et de relever divers défis d’extraction de données.
La caractéristique la plus remarquable de Colly est sa performance remarquable, capable de traiter plus de 1000 requêtes par seconde sur un seul cœur ; ce taux augmente avec les cœurs supplémentaires. Il atteint une telle efficacité grâce à sa mise en cache intégrée et à la prise en charge du scraping synchrone et asynchrone.
Cependant, Colly présente des limites, telles que le manque de rendu JavaScript et une communauté plus petite, ce qui entraîne moins d’extensions et une documentation moindre.
Pour commencer à utiliser Colly, installez d’abord Golang en visitant go.dev . Après l’installation, redémarrez votre ordinateur, ouvrez l’invite de commande en tant qu’administrateur et entrez les commandes :
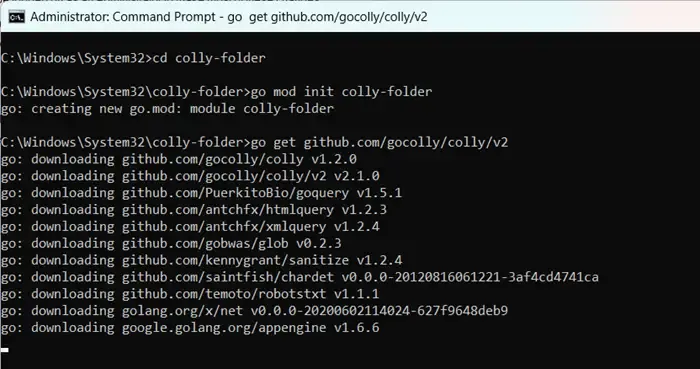
mkdir colly-folder cd colly-folder
go mod init colly-folder
go get github.com/gocolly/colly/v2
Vous pouvez renommer « colly-folder » comme vous le souhaitez. Après avoir créé le module, vous pouvez exécuter votre scraper Web en utilisant go run main.go.
3]PySpider
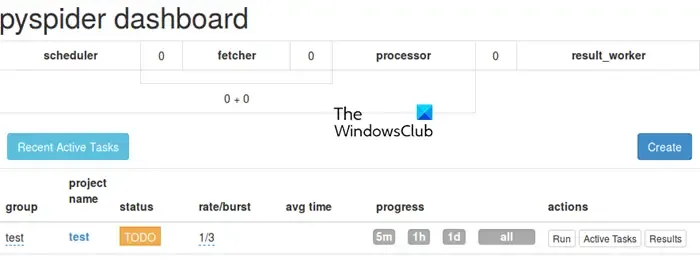
PySpider fonctionne comme un système d’exploration Web complet doté d’une interface utilisateur Web intuitive, simplifiant la gestion et la surveillance de vos robots d’exploration. Il est équipé pour gérer des sites Web riches en JavaScript grâce à son intégration avec PhantomJS.
Contrairement à Colly, PySpider offre des fonctionnalités de gestion de tâches étendues, notamment la planification et la priorisation des tâches, surpassant Crawl4AI à cet égard. Cependant, il convient de noter qu’il peut être en retard en termes de performances par rapport à Crawl4AI en raison de l’architecture asynchrone de ce dernier.
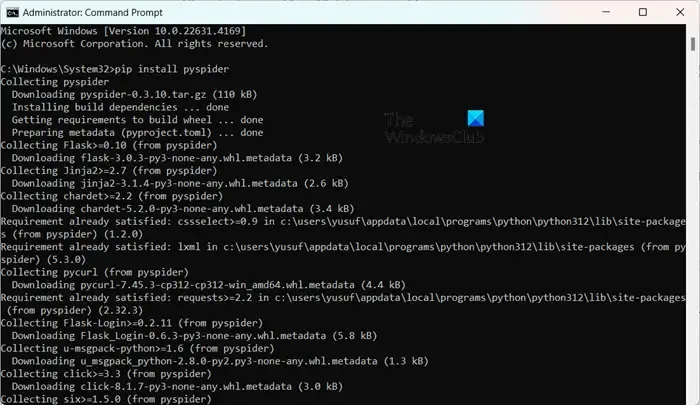
L’installation de PySpider est simple, surtout si vous avez déjà configuré Python. Vous pouvez simplement l’exécuter pip install pyspiderdans une invite de commande avec privilèges élevés. Pour commencer, utilisez simplement la commande pyspideret accédez à l’interface à l’adresse http://localhost:5000/ dans votre navigateur Web.
4] X-Crawl
X-Crawl est une bibliothèque flexible pour Node.js qui utilise des technologies d’IA pour améliorer l’efficacité de l’exploration Web. Cette bibliothèque intègre des fonctionnalités d’IA pour faciliter le développement de robots d’exploration et de scrapers Web efficaces.
X-Crawl excelle dans la gestion du contenu dynamique généré par JavaScript, une nécessité pour de nombreux sites Web modernes. Il propose également de nombreuses options de personnalisation, adaptées pour adapter l’expérience d’exploration à vos besoins.
Il est important de noter certaines distinctions entre Crawl4AI et X-Crawl, principalement basées sur votre langage de programmation préféré : Crawl4AI utilise Python, tandis que X-Crawl est enraciné dans Node.js.
Pour installer X-Crawl, assurez-vous d’avoir Node.js sur votre machine, puis exécutez simplement la commande npm install x-crawl.
5] Feu de camp
Firecrawl, développé par Mendable.ai, est un outil sophistiqué de scraping Web qui transforme les données Web en démarques soigneusement organisées ou en d’autres formats, optimisés pour les modèles de langage volumineux (LLM) et les applications d’IA. Il génère des sorties prêtes à être utilisées par les LLM, facilitant l’intégration de ce contenu dans divers modèles de langage et solutions d’IA. L’outil est livré avec une API facile à utiliser pour soumettre des tâches d’exploration et obtenir des résultats. Pour plus de détails sur Firecrawl, visitez firecrawl.dev , saisissez l’URL du site Web que vous souhaitez analyser et cliquez sur Exécuter.
Quel outil Open Source est optimal pour le développement Web ?
Il existe une multitude d’outils de développement Web open source que vous pouvez utiliser. Pour l’édition de code, pensez à Visual Studio Code ou Atom. Si vous avez besoin de frameworks front-end, Bootstrap et Vue.js sont d’excellents choix, tandis que Django et Express.js sont parfaits pour le développement back-end. De plus, des plateformes comme Git, GitHub, Figma, GIMP, Slack et Trello offrent également des options open source qui peuvent améliorer votre flux de travail de développement Web.
Les modèles GPT open source sont-ils accessibles ?
Oui, il existe plusieurs modèles GPT open source, notamment GPT-Neo d’EleutherAI, Cerebras-GPT, BLOOM, GPT-2 d’OpenAI et Megatron-Turing NLG de NVIDIA/Microsoft. Ces modèles offrent une gamme de solutions adaptées à différentes exigences, du traitement linguistique à usage général aux modèles conçus pour des capacités multilingues ou des tâches à hautes performances.


Laisser un commentaire