
Le dernier brevet de Microsoft génère des avatars virtuels hyperréalistes basés sur les visages des utilisateurs
Microsoft a un faible pour les avatars virtuels : sa plate-forme Mesh récemment lancée permet aux utilisateurs de Teams de créer des avatars pour s’engager dans des espaces dits immersifs virtuels, qui sont des contextes dans lesquels les employés peuvent passer du temps ensemble, virtuellement, même s’ils sont éloignés les uns des autres.
Microsoft Mesh est en effet une plateforme amusante, et le géant de la technologie basé à Redmond affirme que cela fonctionne : de nombreux employés de Microsoft ressentent un sentiment de complicité lorsqu’ils y passent du temps. Mais en même temps, ça ne donne pas l’impression : les avatars ressemblant à des dessins animés, bien que mignons et tout, semblent déplacés.
Cependant, il semble que le géant de la technologie basé à Redmond travaille déjà sur une mise à jour. La société a récemment publié un brevet décrivant une technologie capable de générer des avatars virtuels hyperréalistes basés sur les visages des utilisateurs.
La technologie s’appelle Modélisation et suivi de visage tridimensionnels multimodaux pour générer des avatars expressifs et décrit un système informatique qui crée des avatars expressifs à l’aide de la modélisation et du suivi de visage 3D.
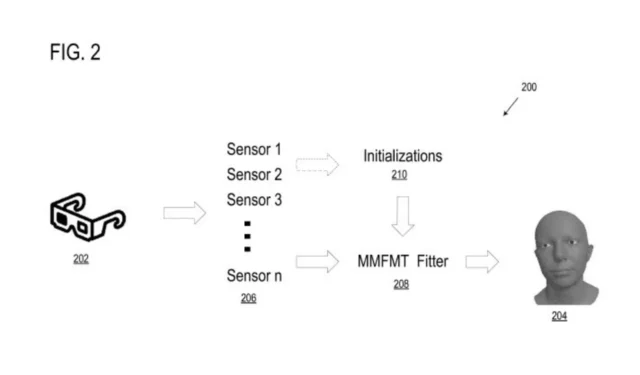
Le système informatique dispose d’un processeur et d’un système de stockage qui lui sont propres, qui traitent et conservent les données nécessaires à la modélisation de l’avatar virtuel hyperréel. Il conserve également des instructions sur la façon de les restituer.
Le processeur reçoit ensuite des données d’initialisation, qui constituent l’apparence de départ d’un modèle de visage, et des signaux de données multimodaux supplémentaires, qui peuvent être des données audio (telles que la voix de l’utilisateur), qui seront utilisés pour créer un modèle hyperréaliste de visage. la face.
Les données d’initialisation et multimodales sont ensuite récupérées par le système et traitées ensemble dans un processus d’ajustement. Ce processus ajuste les données pour les adapter au modèle. Sur la base du processus d’ajustement, le système détermine ensuite un ensemble de paramètres utilisés pour décrire l’avatar virtuel hyperréaliste.
Le système utilise l’apprentissage en profondeur pour créer un avatar virtuel détaillé qui ressemble, agit et est capable d’expressions faciales similaires ou identiques au visage de l’utilisateur. L’apprentissage profond est une forme de technologie d’IA qui cherche à imiter autant que possible le cerveau humain, et Microsoft y a investi ces dernières années.
Puisqu’il s’agit d’un système informatique, le document mentionne la possibilité de l’intégrer sur une multitude d’appareils, des casques VR/AR/MR aux téléphones mobiles, ordinateurs portables, consoles de jeux, tablettes et bien d’autres, ce qui signifie que les utilisateurs pourraient disposer d’un appareil. prêts à transporter leurs avatars virtuels dans un espace virtuel de type Meta ou Mesh.
Microsoft pourrait chercher à implémenter ce nouveau système d’avatar virtuel hyperréaliste sur les plateformes existantes, telles que Microsoft Teams, Microsoft Mesh ou même Windows.
Même si les espaces virtuels existent déjà, ils ne sont pas très populaires pour l’instant en raison de leurs capacités limitées, mais un système comme celui-ci peut encourager davantage de personnes à rejoindre des espaces virtuels.
L’industrie du jeu vidéo pourrait également bénéficier de cette technologie, permettant aux utilisateurs de personnaliser leurs personnages en fonction de leur apparence, offrant ainsi une expérience de jeu hautement personnalisée.
L’article complet peut être lu ici .
Le cadre utilise des techniques d’apprentissage en profondeur et une modélisation directe pour effectuer un processus d’ajustement paramétrique qui traduit les signaux de données multimodaux en un ensemble de paramètres ou de codes d’expression pouvant être utilisés pour générer un modèle facial 3D expressif.
Microsoft
Des techniques de modélisation et de suivi de visage 3D créent des sommets 3D basés sur le visage d’un utilisateur et appliquent des transformations aux sommets à partir d’un visage neutre pour représenter des expressions sur un modèle de visage numérique (par exemple, une représentation d’avatar du visage de l’utilisateur).
Microsoft
Les techniques de modélisation et de suivi de visage 3D multimodales peuvent utiliser de multiples dispositifs de détection différents, chacun fournissant un ou plusieurs signaux d’entrée et/ou mesures pour le visage d’un utilisateur afin de détecter, modéliser, suivre et/ou animer graphiquement un modèle de visage tridimensionnel sous la forme d’un avatar. .
Microsoft


Laisser un commentaire