
Les meilleurs modèles d’apprentissage automatique à connaître
Si vous souhaitez exploiter la puissance de l’intelligence artificielle et de l’apprentissage automatique, vous devez vous familiariser avec certains des meilleurs modèles d’apprentissage automatique. Il existe des dizaines de modèles d’apprentissage automatique, il peut donc être un peu déroutant de choisir des modèles d’apprentissage automatique pour un projet. Dans cet article, nous parlerons de certains des meilleurs modèles d’apprentissage automatique que vous pouvez utiliser en fonction de votre projet.
Les meilleurs modèles d’apprentissage automatique à connaître
Nous avons la liste des modèles et algorithmes d’apprentissage automatique pour les projets, instances et scénarios suivants.
Modèles d’apprentissage automatique pour la prévision des séries chronologiques
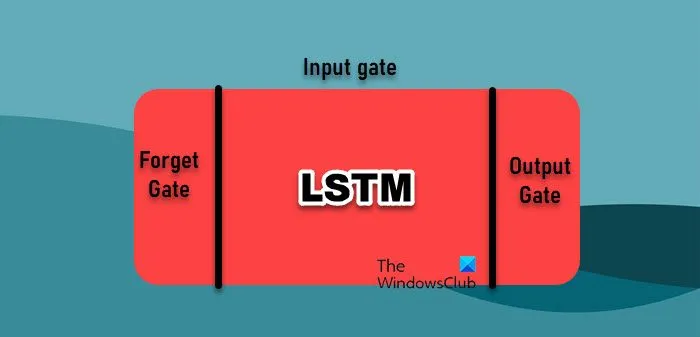
Dans l’analyse des données, la prévision des séries chronologiques repose sur divers algorithmes d’apprentissage automatique, chacun ayant ses propres atouts. Cependant, nous allons parler de deux des plus utilisés.
- Réseau de mémoire à long terme et à court terme : les réseaux de mémoire à long terme et à court terme (LSTM) sont un type de réseau neuronal récurrent (RNN) particulièrement efficace pour l’apprentissage à partir de séquences, ce qui les rend particulièrement adaptés aux données de séries chronologiques. Contrairement aux RNN traditionnels, qui ont du mal à gérer les dépendances à long terme en raison du problème de gradient nul, les LSTM peuvent conserver des informations sur de longues périodes. Cela est rendu possible grâce à leur architecture unique, qui comprend des portes pour gérer le flux d’informations, ce qui leur permet de capturer des modèles complexes dans les données de séries chronologiques.
- Randon Forest : Random Forest est une méthode d’apprentissage d’ensemble (ici deux apprenants ou plus). Pendant l’apprentissage, elle construit plusieurs arbres de décision, puis fait la moyenne de leurs prédictions. Bien qu’elle ne soit pas initialement destinée aux séries chronologiques, elle peut être ajustée pour les prévisions en incluant des variables décalées. Random Forest peut gérer de nombreuses fonctionnalités et est moins susceptible de sur-adapter, ce qui en fait un choix judicieux pour les ensembles de données complexes.
Vous pouvez intégrer ces deux modèles et quelques autres, tels que les modèles VAR, ARIRA et Prophet, pour obtenir le meilleur résultat possible.
Modèles d’apprentissage automatique pour la prévision des cours des actions

Les actions sont aléatoires, mais en même temps, ce caractère aléatoire a aussi un schéma. Si votre projet vise à faire une prévision boursière, nous vous recommandons d’utiliser l’un ou les deux modèles mentionnés ci-dessous.
- Arbre de décision : un arbre de décision est une sorte d’organigramme qui aide à prendre des décisions ou à faire des prédictions. Il comporte des nœuds pour les décisions ou les tests sur les attributs, des branches pour les résultats de ces décisions et des nœuds feuilles pour les résultats finaux ou les prédictions. Chaque nœud interne représente un test sur un attribut, chaque branche représente le résultat du test et chaque nœud feuille représente une étiquette de classe ou une valeur continue.
- Réseau neuronal : les réseaux neuronaux sont des modèles informatiques qui imitent les fonctions complexes du cerveau humain. Ils sont constitués de nœuds ou de neurones interconnectés qui traitent et apprennent des données. Cela permet des tâches telles que la reconnaissance de formes et la prise de décision dans l’apprentissage automatique. Si vous les entraînez bien, ils peuvent fonctionner comme des maîtres des actions.
Cependant, vous devez vous rappeler que déterminer les tendances des stocks peut être très délicat, il ne faut donc pas trop se fier à ces modèles et en intégrer d’autres, tels que Randon Forest et LSTM.
Modèles d’apprentissage automatique pour les classifications multiclasses
Maintenant, parlons de l’une des tâches d’apprentissage automatique les plus courantes : la classification multiclasse. Ici, notre travail consiste à élaborer un modèle qui, à l’aide de données précédentes, peut examiner une information et la classer. Le modèle analyse l’ensemble de données d’entraînement pour trouver des modèles uniques pour chaque classe. Il utilise ensuite ces modèles pour prédire la catégorie des données futures. Deux des algorithmes et modèles les plus courants sont mentionnés ci-dessous.
- Les SVM sont efficaces pour travailler avec de nombreuses informations et trouver des modèles, ils sont donc utiles dans de nombreux domaines différents. Grâce à toutes ces fonctionnalités, ils peuvent être utilisés pour surveiller les données et les classer.
- Il comprend les classificateurs Bayes naïfs multinomiaux, Bayes naïfs de Bernoulli et Bayes naïfs gaussiens. Les classificateurs Bayes naïfs sont un groupe d’algorithmes de classification basés sur le théorème de Bayes. Il ne s’agit pas d’un seul algorithme, mais plutôt d’une famille d’algorithmes qui suivent tous le même principe : chaque paire de caractéristiques classées est indépendante l’une de l’autre.
Vous pouvez également utiliser le réseau neuronal (les détails mentionnés ci-dessus) pour cette fonctionnalité.
Modèle d’apprentissage automatique pour la régression

La régression est utilisée pour prédire la valeur continue, l’une des fonctionnalités les plus nécessaires. C’est pourquoi il existe différents algorithmes en jeu ici. Les deux suivants sont ceux avec lesquels vous devriez commencer.
- Régression linéaire : la régression linéaire est un algorithme largement utilisé dans l’apprentissage automatique. Elle consiste à sélectionner une variable clé dans l’ensemble de données pour prédire les variables de sortie, telles que les valeurs futures. Cet algorithme convient aux cas avec des étiquettes continues, comme la prédiction du nombre de vols quotidiens depuis un aéroport. La représentation de la régression linéaire est y = ax + b.
- Ridge Regression : Ridge Regression est un autre algorithme ML populaire. Il utilise la formule y = Xβ + ϵ. Dans ce cas, « y » représente le vecteur N*1 d’observations pour la variable dépendante, tandis que « X » est la matrice des régresseurs. Les coefficients de régression sont désignés par « β », qui est un vecteur N*1, et « ϵ » représente le vecteur d’erreurs.
Il existe d’autres techniques de régression que vous pouvez utiliser, telles que la régression de réseau neuronal, la régression Lasso, la forêt aléatoire, la régression d’arbre de décision, SVM, la régression polynomiale, la régression gaussienne et le modèle KNN.
Modèle d’apprentissage automatique pour les petits ensembles de données
Si vous traitez un petit ensemble de données, vous pouvez utiliser quelques modèles ML.
- Elastic Net : Elastic Net est une technique qui combine les méthodes de régression Lasso (L1) et Ridge (L2) pour gérer des scénarios avec plusieurs fonctionnalités corrélées. Elle établit un équilibre entre la parcimonie de Lasso et la régularisation de Ridge. La raison pour laquelle Elastic Net est utilisé pour les petits ensembles de données est qu’il est plus efficace pour traiter des prédicteurs hautement corrélés. De plus, comme il combine les régularisations L1 et L2, il peut vous éviter le surajustement plus efficacement que les modèles qui n’utilisent qu’une seule forme de régularisation.
- Réseau neuronal caché unique : dans le cas d’un réseau neuronal caché unique, il n’y a qu’une seule couche de réseau neuronal d’entrée et une seule couche de sortie. La simplicité facilite la mise en œuvre et la compréhension des données, ce dont nous avons besoin lorsque nous traitons de petits ensembles de données. En outre, cela facilite la généralisation et l’interprétation des informations.
Divers autres modèles peuvent être utilisés pour les petits ensembles de données, tels que l’analyse discriminante linéaire, l’analyse discriminante quadratique et le modèle linéaire généralisé, qui sont parmi les plus utiles.
Modèle d’apprentissage automatique pour les grands ensembles de données
Le traitement de grands ensembles de données, ou big data, offre un potentiel d’informations précieuses, mais pose des défis uniques. Vous pouvez utiliser n’importe lequel des modèles que nous avons évoqués précédemment, à l’exception de ceux mentionnés pour les petits et les grands ensembles de données. Cependant, le plus gros problème ici est le traitement d’une telle quantité de données. Les modèles et algorithmes mentionnés ici visent donc à traiter une énorme quantité de données.
- Traitement par lots : le traitement par lots est une technique dans laquelle un grand ensemble de données est divisé en ensembles de données plus petits (lots ou paquets), et le modèle est formé sur chaque lot de manière incrémentielle. Cette méthode permet d’éviter le surapprentissage, un problème courant avec les grands ensembles de données, et rend le processus de formation plus gérable.
- Informatique distribuée : l’informatique distribuée consiste à répartir les données et les tâches sur plusieurs machines ou processeurs afin d’accélérer la formation de modèles d’apprentissage automatique volumineux et complexes. Des frameworks comme Apache Hadoop et Apache Spark fournissent des plateformes robustes pour l’informatique distribuée.
Vous pouvez également utiliser certains des autres modèles ML, tels que la régression linéaire et les réseaux neuronaux, pour les grands ensembles de données.
Quel est le meilleur modèle d’apprentissage automatique ?
Différents modèles d’apprentissage automatique incluent Naive Bayes, KNN, Random Forest, Boosting, AdaBoot, Linear Regression, etc. Cependant, le modèle que vous devez choisir dépend de la situation ou du projet sur lequel vous travaillez. Nous avons mentionné certains des exemples ci-dessus et les meilleurs modèles et algorithmes à utiliser.
Quels sont les 4 modèles d’apprentissage automatique ?
Les quatre modèles d’apprentissage automatique sont le modèle d’apprentissage supervisé, le modèle d’apprentissage non supervisé, le modèle d’apprentissage semi-supervisé et le modèle d’apprentissage par renforcement. Chacun a ses propres avantages, ils doivent donc tous être utilisés ensemble.


Laisser un commentaire