L’IA s’intègre dans votre navigateur et c’est plus rapide que jamais
Nous nous demandions quand utiliseraient-ils toute la puissance de l’IA dans nos navigateurs et, apparemment, le moment est venu.
Nous parlons d’une nouvelle fonctionnalité appelée ONNX Runtime Web qui utilise l’accélérateur WebGPU qui permet de créer des modèles d’IA directement dans le navigateur et de les rendre plus rapides. Beaucoup plus rapide !
Qu’est-ce que le Web d’exécution ONNX ?
Pour expliquer cela, il faut savoir que WebGPU est un moteur, comme WebGL, mais beaucoup plus puissant, capable de gérer des charges de calcul plus importantes. Il s’agit essentiellement d’exploiter la puissance du GPU pour effectuer les tâches de calcul parallèles nécessaires aux processus d’IA.
Maintenant, en arrivant à ONNX Runtime Web, il s’agit d’une bibliothèque JavaScript qui permet aux développeurs Web d’intégrer des LLM directement dans les navigateurs Web et de bénéficier de l’accélération matérielle GPU.
Habituellement, les grands LLM ne sont pas aussi faciles à déployer dans les navigateurs car ils nécessitent beaucoup de mémoire et de puissance de calcul.
L’innovation d’ONNX Runtime Web est qu’il active le backend WebGPU que Microsoft et Intel développent actuellement.
Quelle est la vitesse du runtime Web ONNX ?
Pour prouver son point de vue, l’équipe ONNX Runtime a créé une démo utilisant le modèle Segment Anything , et les résultats ont été tout simplement étonnants.
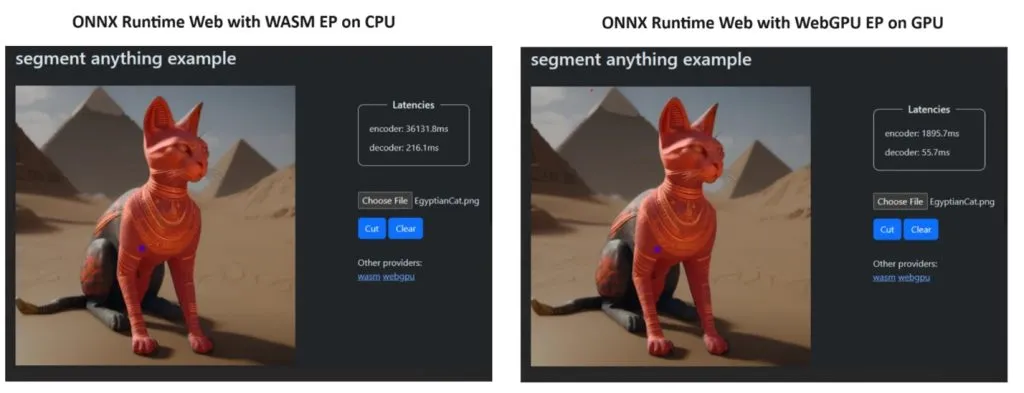
Ils ont intégré WASM EP et WebGPU EP et utilisé un PC NVIDIA GeForce RTX 3060 et Intel Core i9. Ensuite, ils ont comparé l’encodeur utilisant le CPU et le nouveau WebGPU et ce dernier s’est avéré beaucoup plus rapide, comme le montre la capture d’écran ci-dessus.
La bonne nouvelle est que WebGPU est déjà intégré à Chrome 113 et Edge 113 pour Windows, macOS et ChromeOS et Chrome 121 pour Android. Cela signifie que vous pouvez également jouer avec ONNX Runtime Web sur ces navigateurs.
Les développeurs ont expliqué comment essayer ONNX Runtime Web sur la page de leur projet :
Alors, maintenant que tout est en place, commençons à déployer de puissants LLM dans les navigateurs !
Que pensez-vous du nouveau ONNX Runtime Web ? Parlons de ce développement dans la section commentaires ci-dessous.
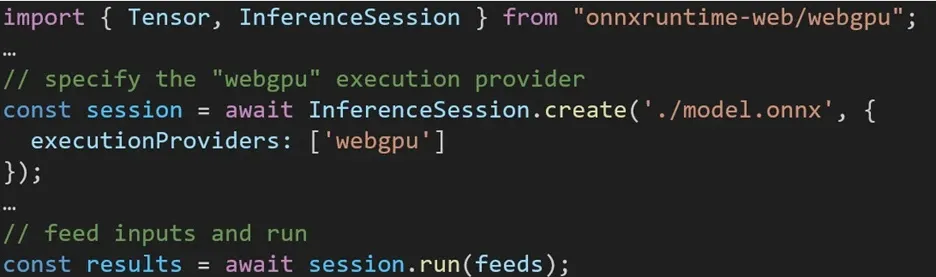
L’expérience d’utilisation de différents backends dans ONNX Runtime Web est simple. Importez simplement le package approprié et créez une session d’inférence Web ONNX Runtime avec le backend requis via le paramètre Execution Provider. Notre objectif est de simplifier le processus pour les développeurs, en leur permettant d’exploiter différentes accélérations matérielles avec un minimum d’effort.
L’extrait de code suivant montre comment appeler l’API Web ONNX Runtime pour inférer un modèle avec WebGPU. Une documentation Web et des exemples supplémentaires d’ONNX Runtime sont accessibles pour approfondir.
Laisser un commentaire