
Découvrez la nouvelle fonctionnalité de Chrome : rendez les fichiers PDF numérisés consultables et modifiables pour un accès au texte sans effort
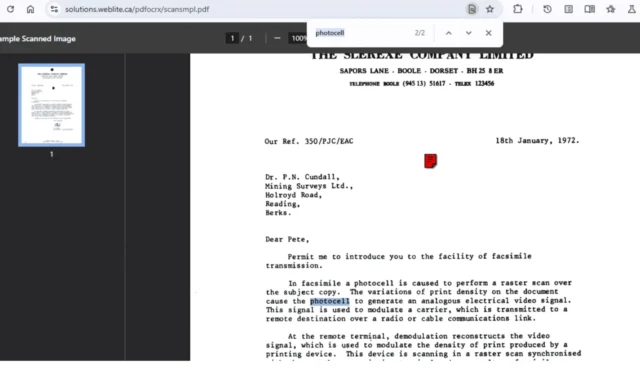
Google teste une nouvelle fonctionnalité de reconnaissance optique de caractères (OCR) dans la visionneuse PDF intégrée de Chrome, conçue pour simplifier le processus d’extraction et de copie de texte à partir de documents PDF numérisés.
Si vous avez déjà rencontré des difficultés pour récupérer du texte à partir d’un PDF numérisé, vous avez peut-être pensé à investir dans des outils OCR coûteux ou à utiliser divers services en ligne. Mais ne vous inquiétez pas ! Chrome, un navigateur que vous utilisez probablement sur les appareils Windows, Mac, Linux et Chromebook, intègre une fonctionnalité OCR intégrée avancée.
Améliorations de l’OCR de Chrome pour l’affichage PDF
Actuellement, Chrome teste une fonctionnalité pour sa visionneuse PDF, appelée « PDF Searchify », accessible via un indicateur de navigateur, qui améliore la capacité de localiser et de reproduire du texte à partir de PDF numérisés.
Auparavant disponibles dans ChromeOS, les fonctionnalités d’extraction de texte s’adressent désormais spécifiquement aux images PDF provenant de scanners, permettant aux utilisateurs d’interagir avec le texte intégré dans ces images. La visionneuse PDF de Chrome améliorée permet de rechercher et de modifier le texte présent dans les images PDF, améliorant ainsi la convivialité et l’accessibilité globale.
La fonctionnalité « PDF Searchify » applique la technologie OCR pour reconnaître le texte des images PDF, le rendant à la fois consultable et modifiable, et est opérationnelle sur Chrome pour Mac, Windows, Linux et ChromeOS.
Pour activer cette fonctionnalité dans Chrome, suivez ces étapes :
- Ouvrez Chrome.
- Aller à chrome://flags.
- Recherchez « Rendre le texte des images PDF interactif ».
- Réglez-le sur « Activé » et redémarrez le navigateur.

Google Chrome propose déjà des fonctions d’extraction de texte via Google Lens intégré, qui permet de traduire et d’extraire du texte à partir de divers supports, y compris des PDF numérisés. Cependant, Google Lens ne prend pas encore en charge la recherche de mots spécifiques dans les images PDF ni la modification du texte extrait.
Cette nouvelle fonctionnalité pourrait bientôt atteindre une version stable dans Chrome. Qu’en pensez-vous ? Êtes-vous impressionné par les avancées de l’OCR dans Chrome ? Partagez vos opinions dans la section commentaires ci-dessous.
De plus, Google Chrome pourrait bientôt lancer un gestionnaire de tâches remanié et permettre la prise en charge des extensions non limitées dans l’Omnibox, permettant à ces extensions d’obtenir des autorisations améliorées pour interagir avec les entrées de la barre d’adresse.


Laisser un commentaire