VLOGGER AI: ahora crea un avatar realista a partir de una foto y usa tu voz para controlarlo
Los investigadores de Google están trabajando para hacer que su tecnología de inteligencia artificial sea cada día más inteligente. Uno de los últimos proyectos de investigación en el que están trabajando es VLOGGER.
VLOGGER se explica como
Según la publicación del blog en GitHub, este enfoque permite la generación de videos de alta calidad con una duración deseable. Sin necesidad de capacitación para cada persona, no depende del recorte de detección de rostros; puede generar la imagen completa y tener en cuenta un amplio espectro, lo cual es importante para sintetizar a los humanos que se comunican.
Por el momento, VLOGGER no está disponible para su uso porque aún está en desarrollo, pero cuando llegue al mercado, podría ser una excelente manera de comunicarse en una videoconferencia a través de Skype, Teams o Slack.
Google confía bastante en el proyecto y lo ha probado mediante varios puntos de referencia; esto es lo que dice:
¿Cómo funciona VLOGGER?
VLOGGER es un marco que actúa como un canal de dos etapas y funciona en una arquitectura de difusión estocástica que transforma texto en imágenes, videos e incluso modelos 3D, pero también agrega un mecanismo de control.
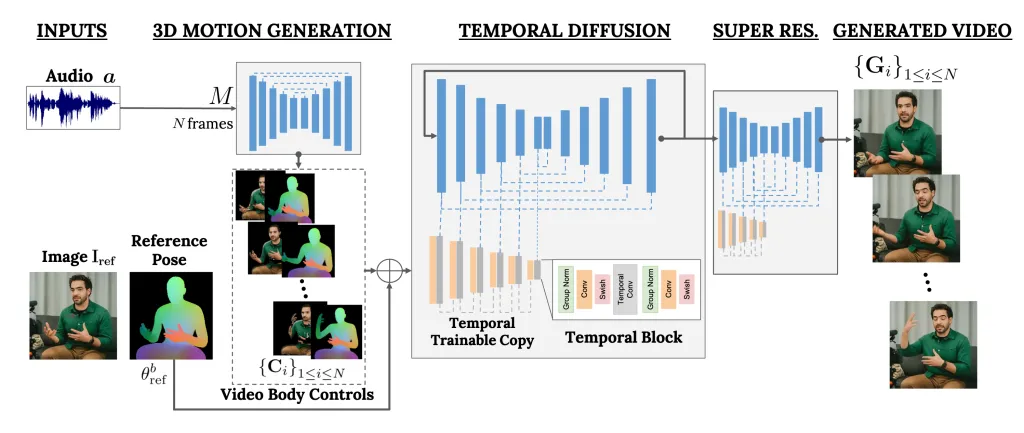
El primer paso es tomar una forma de onda de audio como entrada para generar controles intermedios de movimiento corporal, como la mirada y las expresiones faciales. A continuación, la segunda red utiliza un modelo de traducción temporal de imagen a imagen para identificar estos movimientos y una imagen de referencia de una persona para generar fotogramas para el vídeo.
Otra característica importante de VLOGGER es la capacidad de editar videos existentes. Puede tomar un video y cambiar la expresión de la persona en el video.
Además, el VLOGGER también puede ayudar en la traducción de vídeos; puede tomar un video existente en un idioma específico y editar el área de los labios y la cara para hacerlo consistente con audio nuevo o diferentes idiomas.
Como VLOGGER no es un producto sino un proyecto de investigación y no está completo, no se puede confiar en él. Sí, puede crear movimientos realistas, pero es posible que no pueda igualar cómo se mueve realmente una persona. Dado su modelo de difusión, podría mostrar un comportamiento inusual.
Su equipo también mencionó que no está versado en grandes movimientos o entornos diversos y solo puede trabajar con videos cortos.
¿Crees que podría serte útil? Comparta sus opiniones con nuestros lectores en la sección de comentarios a continuación.
Evaluamos VLOGGER en tres puntos de referencia diferentes y mostramos que el modelo propuesto supera otros métodos de última generación en calidad de imagen, preservación de identidad y consistencia temporal. Recopilamos un nuevo y diverso conjunto de datos MENTOR un orden de magnitud mayor que los anteriores (2.200 horas y 800.000 identidades, y un conjunto de pruebas de 120 horas y 4.000 identidades) sobre el que entrenamos y ablacionamos nuestras principales contribuciones técnicas. Informamos el desempeño de VLOGGER con respecto a múltiples métricas de diversidad, lo que muestra que nuestras elecciones arquitectónicas benefician la capacitación de un modelo justo e imparcial a escala.
Un método para la generación de videos humanos parlantes impulsados por texto y audio a partir de una única imagen de entrada de una persona, que se basa en el éxito de los modelos recientes de difusión generativa.
Nuestro método consta de 1) un modelo estocástico de difusión de movimiento humano a 3D, y 2) una arquitectura novedosa basada en difusión que aumenta los modelos de texto a imagen con controles tanto temporales como espaciales.
Deja una respuesta