
Los mejores modelos de aprendizaje automático que debes conocer
Si desea aprovechar el poder de la inteligencia artificial y el aprendizaje automático, debe conocer algunos de los mejores modelos de aprendizaje automático. Hay docenas de modelos de aprendizaje automático, por lo que puede resultar un poco confuso elegir modelos de aprendizaje automático para un proyecto. En esta publicación, hablaremos sobre algunos de los mejores modelos de aprendizaje automático que puede utilizar según su proyecto.
Los mejores modelos de aprendizaje automático que debes conocer
Tenemos la lista de modelos y algoritmos de aprendizaje automático para los siguientes proyectos, instancias y escenarios.
Modelos de aprendizaje automático para la previsión de series temporales
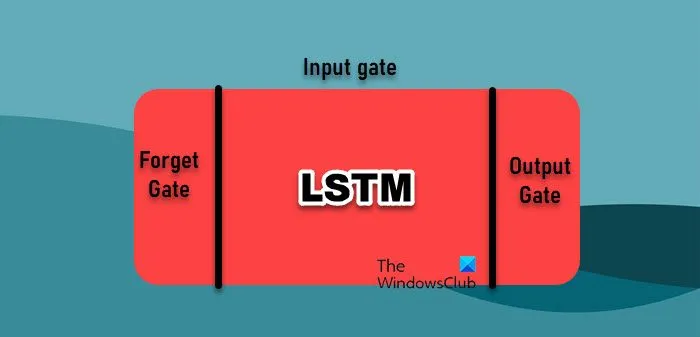
En el análisis de datos, la previsión de series temporales se basa en diversos algoritmos de aprendizaje automático, cada uno con sus propias ventajas. Sin embargo, hablaremos de dos de los más utilizados.
- Red de memoria a corto y largo plazo: las redes de memoria a corto y largo plazo (LSTM) son un tipo de red neuronal recurrente (RNN) que son particularmente eficaces para aprender de secuencias, lo que las hace muy adecuadas para los datos de series temporales. A diferencia de las RNN tradicionales, que tienen problemas con las dependencias a largo plazo debido al problema del gradiente de desaparición, las LSTM pueden retener información durante largos períodos. Esto se logra mediante su arquitectura única, que incluye puertas para gestionar el flujo de información, lo que les permite capturar patrones intrincados en datos de series temporales.
- Bosque aleatorio: el bosque aleatorio es un método de aprendizaje conjunto (aquí, dos o más estudiantes). Durante el entrenamiento, crea múltiples árboles de decisión y luego promedia sus predicciones. Aunque originalmente no está pensado para series temporales, se puede ajustar para realizar pronósticos al incluir variables rezagadas. El bosque aleatorio puede manejar muchas características y es menos probable que se sobreajuste, lo que lo convierte en una opción sólida para conjuntos de datos complejos.
Puede integrar estos dos modelos y algunos otros, como los modelos VAR, ARIRA y Prophet, para lograr el mejor resultado posible.
Modelos de aprendizaje automático para la predicción de acciones

Las acciones son aleatorias, pero al mismo tiempo, esta aleatoriedad también tiene un patrón. Si su proyecto tiene como objetivo realizar una predicción de acciones, le recomendamos utilizar uno o ambos de los modelos mencionados a continuación.
- Árbol de decisiones: un árbol de decisiones es un tipo de diagrama de flujo que ayuda a tomar decisiones o hacer predicciones. Tiene nodos para decisiones o pruebas sobre atributos, ramas para los resultados de estas decisiones y nodos de hoja para los resultados finales o las predicciones. Cada nodo interno representa una prueba sobre un atributo, cada rama representa el resultado de la prueba y cada nodo de hoja representa una etiqueta de clase o un valor continuo.
- Redes neuronales: Las redes neuronales son modelos informáticos que imitan las complejas funciones del cerebro humano. Consisten en nodos o neuronas interconectados que procesan datos y aprenden de ellos. Esto permite realizar tareas como el reconocimiento de patrones y la toma de decisiones en el aprendizaje automático. Si se las entrena bien, pueden funcionar como maestros de las acciones.
Sin embargo, hay que recordar que determinar patrones de existencias puede ser muy complicado, por lo que no hay que confiar demasiado en estos modelos y hay que incorporar otros, como Randon Forest y LSTM.
Modelos de aprendizaje automático para clasificaciones multiclase
Ahora, analicemos uno de los trabajos de aprendizaje automático más comunes: la clasificación multiclase. En este caso, nuestro trabajo consiste en diseñar un modelo que, con la ayuda de datos anteriores, pueda analizar una pieza de información y clasificarla. El modelo analiza el conjunto de datos de entrenamiento para encontrar patrones únicos para cada clase. Luego, utiliza estos patrones para predecir la categoría de los datos futuros. A continuación, se mencionan dos de los algoritmos y modelos más comunes.
- Los SVM son buenos para trabajar con mucha información y encontrar patrones, por lo que son útiles en muchas áreas diferentes. En virtud de todas estas facilidades que proporciona, se puede utilizar para monitorear datos y clasificarlos.
- Incluye el Bayes ingenuo multinomial, el Bayes ingenuo de Bernoulli y el Bayes ingenuo gaussiano. Los clasificadores Bayes ingenuos son un grupo de algoritmos de clasificación basados en el teorema de Bayes. No son solo un algoritmo, sino una familia de algoritmos que siguen el mismo principio: cada par de características que se clasifican son independientes entre sí.
También puede utilizar la red neuronal (los detalles mencionados anteriormente) para esta función.
Modelo de aprendizaje automático para regresión

La regresión se utiliza para predecir valores continuos, una de las características más necesarias. Por eso, existen varios algoritmos en juego. Los dos siguientes son los que deberías utilizar para empezar.
- Regresión lineal: la regresión lineal es un algoritmo muy utilizado en el aprendizaje automático. Implica la selección de una variable clave del conjunto de datos para predecir las variables de salida, como los valores futuros. Este algoritmo es adecuado para casos con etiquetas continuas, como predecir la cantidad de vuelos diarios desde un aeropuerto. La representación de la regresión lineal es y = ax + b.
- Regresión de cresta: la regresión de cresta es otro algoritmo de aprendizaje automático popular. Utiliza la fórmula y = Xβ + ϵ. En este caso, «y» representa el vector N*1 de observaciones para la variable dependiente, mientras que «X» es la matriz de regresores. Los coeficientes de regresión se indican con «β», que es un vector N*1, y «ϵ» representa el vector de errores.
Existen otras técnicas de regresión que puedes utilizar, como la regresión de red neuronal, la regresión Lasso, el bosque aleatorio, la regresión de árbol de decisión, SVM, la regresión polinomial, la regresión gaussiana y el modelo KNN.
Modelo de aprendizaje automático para conjuntos de datos pequeños
Si está trabajando con un conjunto de datos pequeño, hay algunos modelos de aprendizaje automático que puede utilizar.
- Elastic Net: Elastic Net es una técnica que combina los métodos de regresión Lasso (L1) y Ridge (L2) para manejar escenarios con múltiples características correlacionadas. Logra un equilibrio entre la escasez de Lasso y la regularización de Ridge. La razón por la que Elastic Net se utiliza para conjuntos de datos pequeños es que es mejor cuando se trabaja con predictores altamente correlacionados. Además, debido a que combina la regularización L1 y L2, puede evitar el sobreajuste de manera más efectiva en comparación con los modelos que solo usan una forma de regularización.
- Red neuronal oculta única: en el caso de la red neuronal oculta única, solo hay una capa de red neuronal de entrada y una de salida. La simplicidad hace que sea más fácil implementar y comprender los datos, que es lo que necesitamos cuando trabajamos con conjuntos de datos pequeños. Además, hace que sea más fácil generalizar e interpretar la información.
Se pueden utilizar otros modelos para conjuntos de datos pequeños, como el análisis discriminante lineal, el análisis discriminante cuadrático y el modelo lineal generalizado, que son algunos de los más útiles.
Modelo de aprendizaje automático para grandes conjuntos de datos
El procesamiento de grandes conjuntos de datos, o big data, ofrece el potencial de generar información valiosa, pero plantea desafíos únicos. Puede utilizar cualquiera de los modelos que analizamos anteriormente, excepto los mencionados para conjuntos de datos pequeños y grandes. Sin embargo, el mayor problema aquí es procesar una cantidad tan grande de datos. Por lo tanto, los modelos y algoritmos mencionados aquí tienen como objetivo procesar una gran cantidad de datos.
- Procesamiento por lotes: el procesamiento por lotes es una técnica en la que un conjunto de datos grande se divide en conjuntos de datos más pequeños (lotes o paquetes) y el modelo se entrena en cada lote de manera incremental. Este método ayuda a evitar el sobreajuste, un problema común con los conjuntos de datos grandes, y hace que el proceso de entrenamiento sea más manejable.
- Computación distribuida: la computación distribuida implica distribuir datos y tareas entre varias máquinas o procesadores para acelerar el entrenamiento de modelos de aprendizaje automático grandes y complejos. Los marcos como Apache Hadoop y Apache Spark brindan plataformas sólidas para la computación distribuida.
También puede utilizar algunos de los otros modelos de ML, como regresión lineal y redes neuronales, para conjuntos de datos grandes.
¿Cuál es el mejor modelo de aprendizaje automático?
Entre los distintos modelos de aprendizaje automático se incluyen Naive Bayes, KNN, Random Forest, Boosting, AdaBoot, Linear Regression y más. Sin embargo, el modelo que debes elegir depende de la situación o del proyecto en el que estés trabajando. Hemos mencionado algunos de los casos anteriores y los mejores modelos y algoritmos para utilizar.
¿Cuáles son los 4 modelos de aprendizaje automático?
Los cuatro modelos de aprendizaje automático son el modelo de aprendizaje supervisado, el modelo de aprendizaje no supervisado, el modelo de aprendizaje semisupervisado y el modelo de aprendizaje de refuerzo. Cada uno tiene sus propias ventajas, por lo que se deben utilizar todos juntos.


Deja una respuesta