
Descubra la nueva función de Chrome: haga que los archivos PDF escaneados se puedan buscar y editar para acceder al texto sin esfuerzo
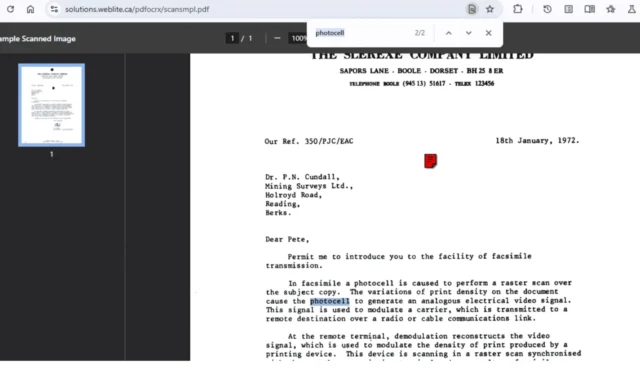
Google está probando una nueva función de reconocimiento óptico de caracteres (OCR) dentro del visor de PDF integrado de Chrome, diseñada para simplificar el proceso de extracción y copia de texto de documentos PDF escaneados.
Si en el pasado ha tenido dificultades para recuperar texto de un PDF escaneado, es posible que haya pensado en invertir en costosas herramientas de OCR o utilizar varios servicios en línea. Sin embargo, ¡no hay de qué preocuparse! Chrome, un navegador que probablemente utilice en dispositivos Windows, Mac, Linux y Chromebook, está incorporando una funcionalidad avanzada de OCR integrada.
Mejoras en el OCR de Chrome para la visualización de PDF
Actualmente, Chrome está probando una función para su visor de PDF, conocida como «PDF Searchify», a la que se puede acceder a través de una bandera del navegador, que mejora la capacidad de localizar y replicar texto de archivos PDF escaneados.
Las funciones de extracción de texto, que antes estaban disponibles en ChromeOS, ahora se adaptan específicamente a las imágenes PDF de los escáneres, lo que permite a los usuarios interactuar con el texto incrustado en estas imágenes. El visor de PDF de Chrome actualizado permite buscar y editar el texto presente en las imágenes PDF, lo que mejora la usabilidad y la accesibilidad general.
La función “PDF Searchify” aplica tecnología OCR para reconocer texto de imágenes PDF, lo que permite realizar búsquedas y editarlo, y está operativa en Chrome para Mac, Windows, Linux y ChromeOS.
Para activar esta función en Chrome, siga estos pasos:
- Abre Chrome.
- Ir a chrome://flags.
- Busque “ Hacer que el texto en imágenes PDF sea interactivo ”.
- Configúrelo en “Habilitado” y reinicie el navegador.

Google Chrome ya ofrece funciones de extracción de texto a través de Google Lens integrado, que puede traducir y extraer texto de diversos medios, incluidos archivos PDF escaneados. Sin embargo, Google Lens aún no permite buscar palabras específicas dentro de imágenes PDF ni editar el texto extraído.
Es posible que esta nueva función llegue pronto a una versión estable de Chrome. ¿Qué opinas? ¿Te impresionan los avances del OCR en Chrome? Comparte tu opinión en la sección de comentarios a continuación.
Además, Google Chrome podría lanzar pronto un Administrador de tareas renovado y habilitar soporte para extensiones sin ámbito dentro del Omnibox, otorgando a estas extensiones permisos mejorados para interactuar con las entradas de la barra de direcciones.


Deja una respuesta