
La IA llega a tu navegador y es más rápida que nunca
Nos preguntábamos cuándo utilizarán todo el poder de la IA en nuestros navegadores y, aparentemente, ha llegado el momento.
Estamos hablando de una nueva característica llamada ONNX Runtime Web que utiliza el acelerador WebGPU que permite integrar modelos de IA directamente en el navegador y hacerlos más rápidos. ¡Mucho más rápido!
¿Qué es ONNX Runtime Web?
Para explicar esto, necesita saber que WebGPU es un motor, como WebGL, pero mucho más potente, capaz de manejar cargas de trabajo computacionales más grandes. Básicamente, se trata de aprovechar la potencia de la GPU para realizar tareas computacionales paralelas necesarias en los procesos de IA.
Ahora, llegando a ONNX Runtime Web, es una biblioteca de JavaScript que permite a los desarrolladores web integrar LLM directamente en los navegadores web y beneficiarse de la aceleración del hardware de la GPU.
Por lo general, los LLM grandes no se implementan tan fácilmente en los navegadores porque requieren mucha memoria y potencia computacional.
La innovación de ONNX Runtime Web es que habilita el backend WebGPU que Microsoft e Intel están desarrollando actualmente.
¿Qué tan rápido es ONNX Runtime Web?
Para demostrar su punto, el equipo de ONNX Runtime creó una demostración utilizando el modelo Segment Anything y los resultados fueron sorprendentes.
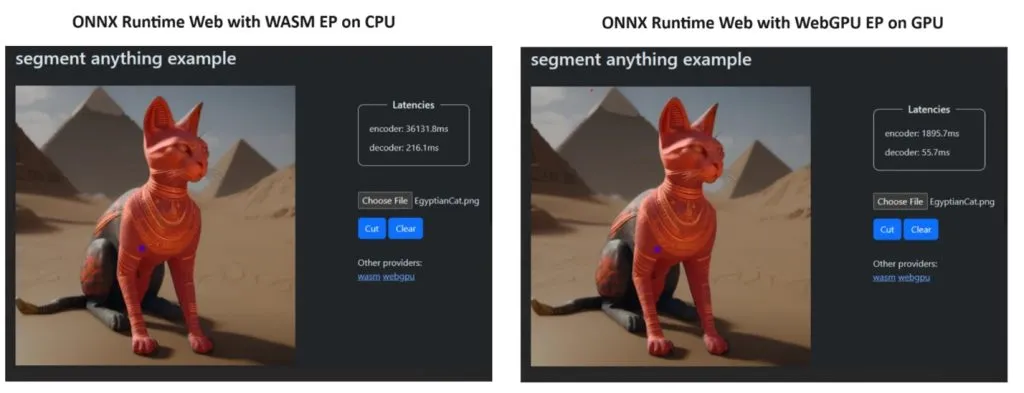
Incorporaron WASM EP y WebGPU EP y utilizaron una PC NVIDIA GeForce RTX 3060 y Intel Core i9. Luego, compararon el codificador usando la CPU y la nueva WebGPU y esta última demostró ser mucho más rápida, como se muestra en la captura de pantalla anterior.
La buena noticia es que WebGPU ya está integrado en Chrome 113 y Edge 113 para Windows, macOS y ChromeOS y Chrome 121 para Android. Eso significa que también puedes jugar con ONNX Runtime Web en estos navegadores.
Los desarrolladores explicaron cómo probar ONNX Runtime Web en la página de su proyecto:
Entonces, ahora que tenemos todo listo, ¡comencemos a implementar algunos LLM potentes en los navegadores!
¿Qué opinas del nuevo ONNX Runtime Web? Hablemos de este desarrollo en la sección de comentarios a continuación.
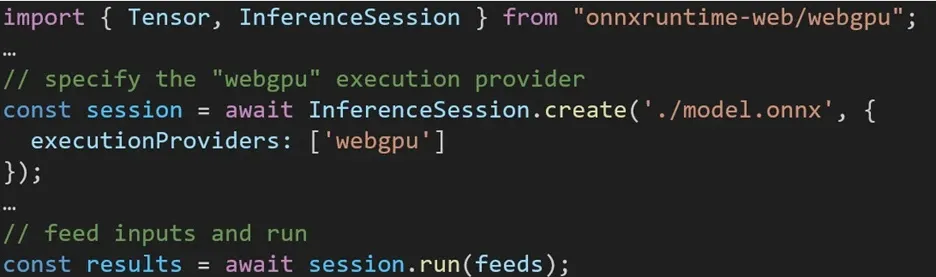
La experiencia al utilizar diferentes backends en ONNX Runtime Web es sencilla. Simplemente importe el paquete relevante y cree una sesión de inferencia web ONNX Runtime con el backend requerido a través de la configuración del Proveedor de ejecución. Nuestro objetivo es simplificar el proceso para los desarrolladores, permitiéndoles aprovechar diferentes aceleraciones de hardware con el mínimo esfuerzo.
El siguiente fragmento de código muestra cómo llamar a ONNX Runtime Web API para inferir un modelo con WebGPU. Se puede acceder a documentación y ejemplos adicionales de ONNX Runtime Web para profundizar más.


Deja una respuesta