Top Open Source Alternatives to Crawl4AI: Best Options Compared
Crawl4AI serves as a complimentary tool for web crawling and data extraction, particularly catering to the requirements of large language models (LLMs) and numerous AI-based applications. Nevertheless, it is not the sole contender in this space. In this article, we will explore the top open-source alternatives to Crawl4AI.
Leading Open Source Alternatives to Crawl4AI
Below are some notable open-source alternatives to Crawl4AI.
- Scrapy
- Collie
- PySpider
- X-Crawl
- Firecrawl
1] Scrappy

Scrapy stands out as a Python-based open-source framework designed for web scraping and crawling. It efficiently enables users to extract data from web pages. Thanks to its use of Twisted, an asynchronous networking framework, Scrapy enhances performance and processing speed.
This framework supports the addition of middleware and pipelines, allowing for customized data processing. Scrapy is adept at managing requests, tracing links, and extracting information using CSS selectors and XPath, seamlessly blending into your current environment.
Additionally, Scrapy offers a user-friendly interface, simplifying the process of tracking and extracting data from various websites. The platform is supported by a vibrant community and comprehensive documentation.
To install Scrapy, ensure you are using Python 3.8 or higher (CPython is the default, but PyPy is also supported). If you are utilizing Anaconda or Miniconda, install the package via the conda-forge channel with the following command:
conda install -c conda-forge scrapy
Alternatively, for those who prefer PyPI, execute the command in an elevated Command Prompt:
pip install Scrapy
To delve deeper into this tool, visit scrapy.org.
2] Collie
Colly is a straightforward scraping library developed for Golang. It simplifies the process of sending HTTP requests, HTML parsing, and retrieving data from websites. Colly features functions that enable developers to navigate web pages, filter elements using CSS selectors, and tackle various data extraction challenges.
The standout feature of Colly is its remarkable performance, capable of processing over 1000 requests per second on a single core; this rate increases with additional cores. It achieves such efficiency due to its built-in caching and support for both synchronous and asynchronous scraping.
However, Colly does have limitations, such as the lack of JavaScript rendering and a smaller community, leading to fewer extensions and lesser documentation.
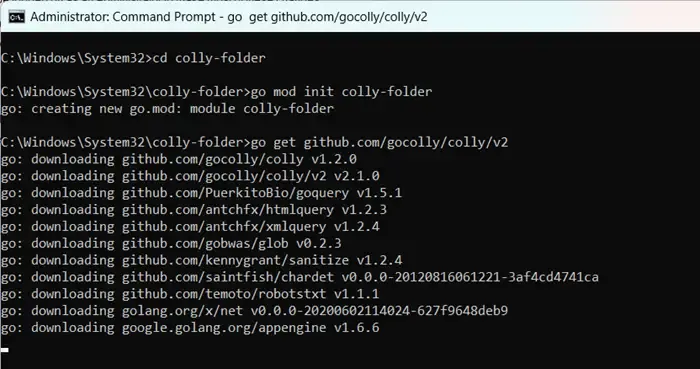
To get started with Colly, first install Golang by visiting go.dev. After installation, restart your computer, open the Command Prompt as an administrator, and enter the commands:
mkdir colly-folder cd colly-folder
go mod init colly-folder
go get github.com/gocolly/colly/v2
You can rename “colly-folder”to anything you prefer. After building the module, you can run your web scraper using go run main.go.
3] PySpider
PySpider operates as a comprehensive web crawling system featuring an intuitive web-based user interface, simplifying the management and monitoring of your crawlers. It is equipped to handle websites rich in JavaScript through its integration with PhantomJS.
Unlike Colly, PySpider offers extensive task management capabilities, including scheduling and prioritizing tasks, outperforming Crawl4AI in this regard. However, it is worth noting that it may lag in performance when set against Crawl4AI due to the latter’s async architecture.
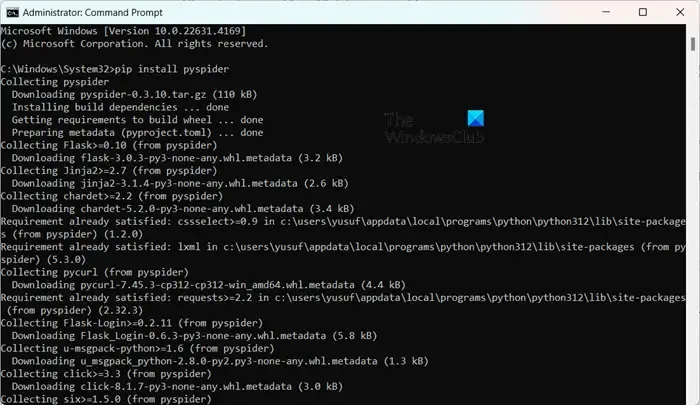
Installing PySpider is uncomplicated, especially if you already have Python set up. You can simply execute pip install pyspider in an elevated Command Prompt. To start, just use the command pyspider and access the interface at http://localhost:5000/ in your web browser.
4] X-Crawl
X-Crawl is a flexible library for Node.js that utilizes AI technologies to enhance web crawling efficiency. This library integrates AI capabilities to facilitate the development of effective web crawlers and scrapers.
X-Crawl excels at managing dynamic content generated by JavaScript, a necessity for many modern websites. It also provides numerous customization options, tailored to fine-tune the crawling experience to your needs.
It’s important to note some distinctions between Crawl4AI and X-Crawl, predominantly based on your preferred programming language—Crawl4AI uses Python, while X-Crawl is rooted in Node.js.
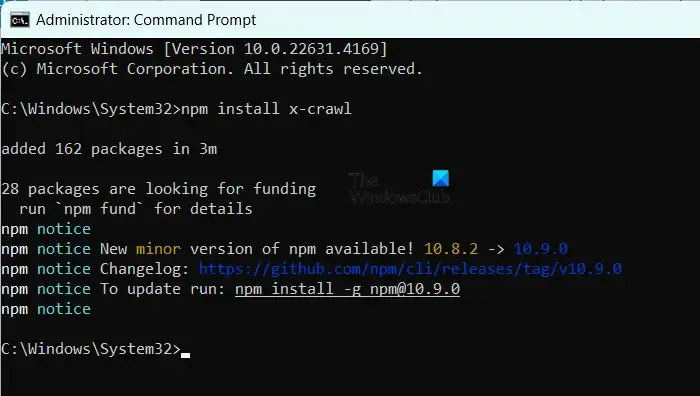
To install X-Crawl, ensure you have Node.js on your machine, then simply run the command npm install x-crawl.
5] Firecrawl
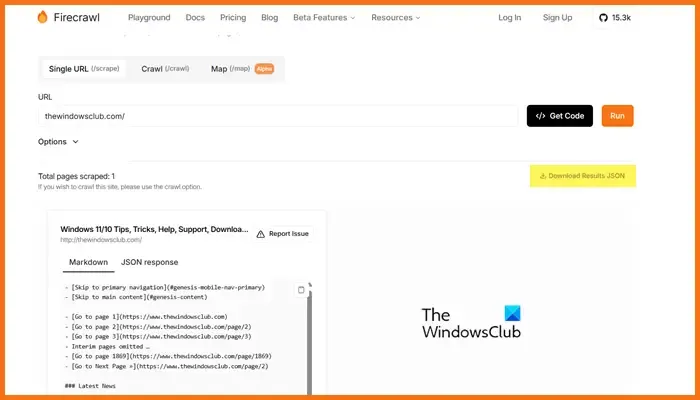
Firecrawl, developed by Mendable.ai, is a sophisticated web scraping tool that transforms web data into neatly organized markdowns or other formats, optimized for large language models (LLMs) and AI applications. It generates outputs that are ready for LLM use, facilitating the integration of this content into diverse language models and AI solutions. The tool comes with an easy-to-use API to submit crawling jobs and obtain results. For more details on Firecrawl, visit firecrawl.dev, enter the website URL you wish to scan, and click on Run.
Which Open Source Tool is Optimal for Web Development?
A plethora of open-source web development tools are available for you to utilize. For code editing, consider Visual Studio Code or Atom. If you’re in need of frontend frameworks, Bootstrap and Vue.js are excellent choices, while Django and Express.js serve well for backend development. Additionally, platforms like Git, GitHub, Figma, GIMP, Slack, and Trello also offer open-source options that can enhance your web development workflow.
Are Open Source GPT Models Accessible?
Yes, various open-source GPT models exist, including GPT-Neo by EleutherAI, Cerebras-GPT, BLOOM, OpenAI’s GPT-2, and NVIDIA/Microsoft’s Megatron-Turing NLG. These models provide a range of solutions to suit different requirements, from general-purpose language processing to models crafted for multilingual capabilities or high-performance tasks.
Leave a Reply