
VLOGGER AI: Erstellen Sie jetzt einen lebensechten Avatar aus einem Foto und steuern Sie ihn mit Ihrer Stimme
Forscher bei Google arbeiten jeden Tag daran, seine KI-Technologie intelligenter zu machen. Eines der neuesten Forschungsprojekte, an denen sie arbeiten, ist VLOGGER.
VLOGGER wird erklärt als
Laut dem Blogbeitrag auf GitHub ermöglicht dieser Ansatz die Erstellung hochwertiger Videos mit gewünschter Länge. Da keine Schulung für jede Person erforderlich ist, kommt es nicht auf das Zuschneiden der Gesichtserkennung an; Es kann das vollständige Bild erzeugen und ein breites Spektrum berücksichtigen, was für die Synthese kommunizierender Menschen wichtig ist.
Derzeit ist VLOGGER noch nicht verfügbar, da es sich noch in der Entwicklung befindet. Wenn es jedoch auf den Markt kommt, könnte es eine großartige Möglichkeit sein, in einer Videokonferenz über Skype, Teams oder Slack zu kommunizieren.
Google ist von dem Projekt durchaus überzeugt und hat es anhand verschiedener Benchmarks getestet; Hier ist, was es sagt:
Wie funktioniert VLOGGER?
VLOGGER ist ein Framework, das als zweistufige Pipeline fungiert und auf einer stochastischen Diffusionsarchitektur arbeitet, die Text in Bilder, Videos und sogar 3D-Modelle umwandelt, aber auch einen Kontrollmechanismus hinzufügt.
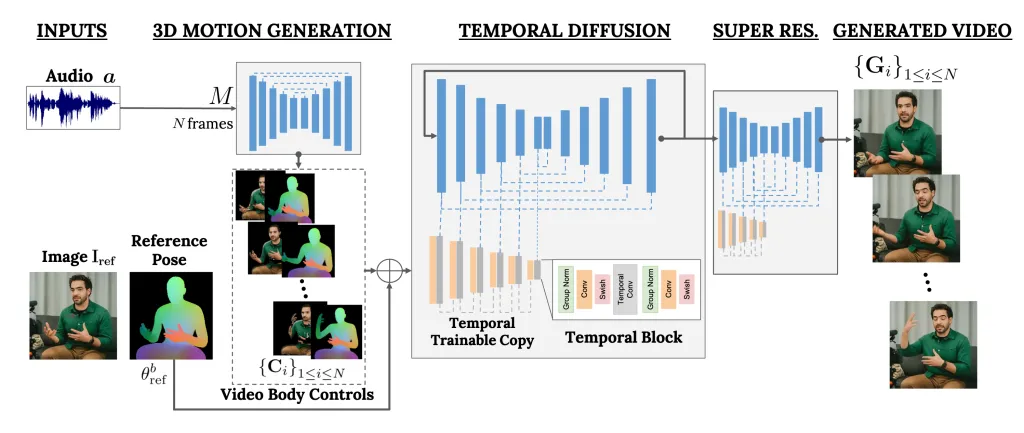
Der erste Schritt besteht darin, eine Audiowellenform als Eingabe zu verwenden, um intermediäre Körperbewegungssteuerungen wie Blick und Gesichtsausdrücke zu generieren. Als nächstes verwendet das zweite Netzwerk ein zeitliches Bild-zu-Bild-Übersetzungsmodell, um diese Bewegungen zu identifizieren, und ein Referenzbild einer Person, um Frames für das Video zu generieren.
Ein weiteres wichtiges Feature von VLOGGER ist die Möglichkeit, vorhandene Videos zu bearbeiten. Es kann ein Video aufnehmen und den Gesichtsausdruck der Person im Video verändern.
Darüber hinaus kann der VLOGGER auch bei der Videoübersetzung helfen; Es kann ein vorhandenes Video in einer bestimmten Sprache aufnehmen und den Lippen- und Gesichtsbereich bearbeiten, um es mit neuem Audio oder anderen Sprachen in Einklang zu bringen.
Da es sich bei VLOGGER nicht um ein Produkt, sondern um ein Forschungsprojekt handelt und es nicht vollständig ist, kann man sich nicht darauf verlassen. Ja, es kann realistische Bewegungen erzeugen, aber es kann sein, dass es nicht mit der tatsächlichen Bewegung einer Person übereinstimmt. Aufgrund seines Diffusionsmodells könnte es ungewöhnliches Verhalten zeigen.
Das Team erwähnte auch, dass es sich nicht mit großen Bewegungen oder unterschiedlichen Umgebungen auskenne und nur für kurze Videos geeignet sei.
Glauben Sie, dass es für Sie hilfreich sein könnte? Teilen Sie Ihre Meinung mit unseren Lesern im Kommentarbereich unten
Wir bewerten VLOGGER anhand von drei verschiedenen Benchmarks und zeigen, dass das vorgeschlagene Modell andere hochmoderne Methoden in Bezug auf Bildqualität, Identitätserhaltung und zeitliche Konsistenz übertrifft. Wir sammeln einen neuen und vielfältigen MENTOR-Datensatz, der um eine Größenordnung größer ist als die vorherigen (2.200 Stunden und 800.000 Identitäten sowie ein Testsatz von 120 Stunden und 4.000 Identitäten), an dem wir unsere wichtigsten technischen Beiträge trainieren und abarbeiten. Wir berichten über die Leistung von VLOGGER in Bezug auf mehrere Diversitätsmetriken und zeigen, dass unsere Architekturentscheidungen der Schulung eines fairen und unvoreingenommenen Modells im großen Maßstab zugute kommen.
Eine Methode zur text- und audiogesteuerten Generierung sprechender menschlicher Videos aus einem einzigen Eingabebild einer Person, die auf dem Erfolg neuerer generativer Diffusionsmodelle aufbaut.
Unsere Methode besteht aus 1) einem stochastischen Diffusionsmodell von Mensch zu 3D-Bewegung und 2) einer neuartigen, auf Diffusion basierenden Architektur, die Text-zu-Bild-Modelle sowohl um zeitliche als auch räumliche Kontrollen erweitert.


Schreibe einen Kommentar