
Die besten Machine-Learning-Modelle, die Sie kennen sollten
Wenn Sie die Leistungsfähigkeit künstlicher Intelligenz und maschinellen Lernens nutzen möchten, müssen Sie einige der besten Modelle für maschinelles Lernen kennen. Es gibt Dutzende von Modellen für maschinelles Lernen, daher kann die Auswahl von Modellen für maschinelles Lernen für ein Projekt etwas verwirrend sein. In diesem Beitrag sprechen wir über einige der besten Modelle für maschinelles Lernen, die Sie je nach Projekt verwenden können.
Die besten Machine-Learning-Modelle, die Sie kennen sollten
Wir haben die Liste der Modelle und Algorithmen des maschinellen Lernens für die folgenden Projekte, Instanzen und Szenarien.
Machine-Learning-Modelle für die Zeitreihenprognose
Bei der Datenanalyse stützt sich die Zeitreihenprognose auf verschiedene Algorithmen des maschinellen Lernens, von denen jeder seine eigenen Stärken hat. Wir werden jedoch über zwei der am häufigsten verwendeten sprechen.
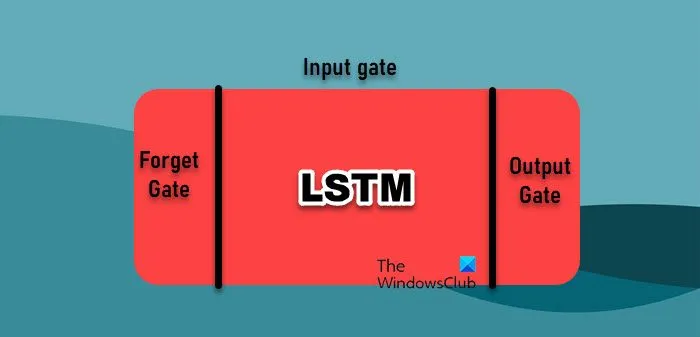
- Netzwerk mit langem Kurzzeitgedächtnis: Netzwerke mit langem Kurzzeitgedächtnis (LSTM) sind eine Art rekurrentes neuronales Netzwerk (RNN), das besonders effektiv beim Lernen aus Sequenzen ist und sich daher gut für Zeitreihendaten eignet. Im Gegensatz zu herkömmlichen RNNs, die aufgrund des Problems des verschwindenden Gradienten mit langfristigen Abhängigkeiten zu kämpfen haben, können LSTMs Informationen über lange Zeiträume hinweg speichern. Dies wird durch ihre einzigartige Architektur erreicht, die Gates zur Verwaltung des Informationsflusses enthält, wodurch sie komplexe Muster in Zeitreihendaten erfassen können.
- Random Forest: Random Forest ist eine Ensemble-Lernmethode (hier zwei oder mehr Lernende). Während des Trainings werden mehrere Entscheidungsbäume erstellt und dann der Durchschnitt ihrer Vorhersagen berechnet. Obwohl es ursprünglich nicht für Zeitreihen gedacht ist, kann es durch die Einbeziehung verzögerter Variablen für die Prognose angepasst werden. Random Forest kann viele Funktionen verarbeiten und neigt weniger zu Überanpassung, was es zu einer guten Wahl für komplexe Datensätze macht.
Sie können diese beiden Modelle und einige andere, wie z. B. VAR-, ARIRA- und Prophet-Modelle, integrieren, um das bestmögliche Ergebnis zu erzielen.
Modelle des maschinellen Lernens zur Aktienprognose

Aktien sind zufällig, doch gleichzeitig folgt diese Zufälligkeit auch einem Muster. Wenn Ihr Projekt auf eine Aktienprognose abzielt, empfehlen wir die Verwendung eines oder beider der unten genannten Modelle.
- Entscheidungsbaum: Ein Entscheidungsbaum ist eine Art Flussdiagramm, das bei der Entscheidungsfindung oder Vorhersage hilft. Er hat Knoten für Entscheidungen oder Tests von Attributen, Zweige für die Ergebnisse dieser Entscheidungen und Blattknoten für die endgültigen Ergebnisse oder Vorhersagen. Jeder interne Knoten stellt einen Test eines Attributs dar, jeder Zweig stellt das Ergebnis des Tests dar und jeder Blattknoten stellt eine Klassenbezeichnung oder einen kontinuierlichen Wert dar.
- Neuronales Netzwerk: Neuronale Netzwerke sind Computermodelle, die die komplexen Funktionen des menschlichen Gehirns nachahmen. Sie bestehen aus miteinander verbundenen Knoten oder Neuronen, die Daten verarbeiten und daraus lernen. Dies ermöglicht Aufgaben wie Mustererkennung und Entscheidungsfindung im maschinellen Lernen. Wenn Sie sie gut trainieren, können sie als Meister der Aktien fungieren.
Sie müssen jedoch bedenken, dass das Herausfinden von Bestandsmustern sehr schwierig sein kann. Daher sollten Sie sich nicht zu sehr auf diese Modelle verlassen und andere einbeziehen, wie etwa Randon Forest und LSTM.
Machine-Learning-Modelle für Multiklassen-Klassifikationen
Lassen Sie uns nun eine der häufigsten Aufgaben des maschinellen Lernens besprechen: die Multiklassenklassifizierung. Hier besteht unsere Aufgabe darin, ein Modell zu entwerfen, das mithilfe früherer Daten eine Information betrachten und klassifizieren kann. Das Modell analysiert den Trainingsdatensatz, um eindeutige Muster für jede Klasse zu finden. Anschließend verwendet es diese Muster, um die Kategorie zukünftiger Daten vorherzusagen. Zwei der häufigsten Algorithmen und Modelle werden unten erwähnt.
- SVMs können gut mit großen Informationsmengen arbeiten und Muster erkennen, daher sind sie in vielen verschiedenen Bereichen nützlich. Dank all dieser Funktionen können sie zur Überwachung und Klassifizierung von Daten verwendet werden.
- Dazu gehören Multinomial Naive Bayes, Bernoulli Naive Bayes und Gaussian Naive Bayes. Naive Bayes-Klassifikatoren sind eine Gruppe von Klassifizierungsalgorithmen, die auf dem Bayes-Theorem basieren. Sie sind nicht nur ein Algorithmus, sondern eine Familie von Algorithmen, die alle demselben Prinzip folgen: Jedes zu klassifizierende Merkmalspaar ist unabhängig voneinander.
Sie können für diese Funktion auch das neuronale Netzwerk (die Details sind oben aufgeführt) verwenden.
Maschinelles Lernmodell für Regression

Regression wird verwendet, um kontinuierliche Werte vorherzusagen, eine der am meisten benötigten Funktionen. Deshalb sind hier verschiedene Algorithmen im Spiel. Mit den folgenden beiden sollten Sie beginnen.
- Lineare Regression: Die lineare Regression ist ein weit verbreiteter Algorithmus im maschinellen Lernen. Dabei wird eine Schlüsselvariable aus dem Datensatz ausgewählt, um die Ausgabevariablen, z. B. zukünftige Werte, vorherzusagen. Dieser Algorithmus eignet sich für Fälle mit kontinuierlichen Beschriftungen, z. B. die Vorhersage der Anzahl der täglichen Flüge von einem Flughafen. Die Darstellung der linearen Regression ist y = ax + b.
- Ridge-Regression: Ridge-Regression ist ein weiterer beliebter ML-Algorithmus. Er verwendet die Formel y = Xβ + ϵ. In diesem Fall stellt „y“ den N*1-Vektor der Beobachtungen für die abhängige Variable dar, während „X“ die Matrix der Regressoren ist. Die Regressionskoeffizienten werden durch „β“ gekennzeichnet, was ein N*1-Vektor ist, und „ϵ“ steht für den Fehlervektor.
Es gibt noch andere Regressionstechniken, die Sie verwenden können, wie etwa neuronale Netzregression, Lasso-Regression, Random Forest, Entscheidungsbaum-Regression, SVM, Polynomregression, Gauß-Regression und KNN-Modell.
Maschinelles Lernmodell für kleine Datensätze
Wenn Sie mit einem kleinen Datensatz arbeiten, können Sie einige ML-Modelle verwenden.
- Elastic Net: Elastic Net ist eine Technik, die Lasso- (L1) und Ridge- (L2) Regressionsmethoden kombiniert, um Szenarien mit mehreren korrelierten Merkmalen zu verarbeiten. Es schafft ein Gleichgewicht zwischen Lassos Spärlichkeit und Ridges Regularisierung. Der Grund, warum Elastic Net für kleine Datensätze verwendet wird, ist, dass es besser ist, wenn es mit stark korrelierten Prädiktoren zu tun hat. Da es außerdem sowohl L1- als auch L2-Regularisierung kombiniert, kann es Sie im Vergleich zu Modellen, die nur eine Form der Regularisierung verwenden, effektiver vor Überanpassung schützen.
- Einzelnes verstecktes neuronales Netzwerk: Im Fall eines einzelnen versteckten neuronalen Netzwerks gibt es nur eine Eingabe- und eine Ausgabeschicht des neuronalen Netzwerks. Die Einfachheit erleichtert die Implementierung und das Verständnis der Daten, was wir beim Umgang mit kleinen Datensätzen benötigen. Außerdem erleichtert es die Verallgemeinerung und Interpretation von Informationen.
Für kleine Datensätze können verschiedene andere Modelle verwendet werden, wie etwa die lineare Diskriminanzanalyse, die quadratische Diskriminanzanalyse und das verallgemeinerte lineare Modell, die zu den nützlichsten zählen.
Maschinelles Lernmodell für große Datensätze
Die Verarbeitung großer Datensätze oder Big Data bietet das Potenzial für wertvolle Erkenntnisse, bringt aber auch einzigartige Herausforderungen mit sich. Sie können jedes der zuvor besprochenen Modelle verwenden, mit Ausnahme der für kleine und große Datensätze genannten. Das größte Problem hierbei ist jedoch die Verarbeitung einer so großen Datenmenge. Die hier erwähnten Modelle und Algorithmen zielen daher darauf ab, eine riesige Datenmenge zu verarbeiten.
- Stapelverarbeitung: Bei der Stapelverarbeitung wird ein großer Datensatz in kleinere Datensätze (Stapel oder Pakete) aufgeteilt und das Modell wird schrittweise mit jedem Stapel trainiert. Diese Methode hilft, Überanpassung zu vermeiden, ein häufiges Problem bei großen Datensätzen, und macht den Trainingsprozess besser handhabbar.
- Verteiltes Rechnen: Verteiltes Rechnen bedeutet, Daten und Aufgaben auf mehrere Maschinen oder Prozessoren zu verteilen, um das Training großer und komplexer Modelle für maschinelles Lernen zu beschleunigen. Frameworks wie Apache Hadoop und Apache Spark bieten leistungsstarke Plattformen für verteiltes Rechnen.
Sie können für große Datensätze auch einige der anderen ML-Modelle verwenden, z. B. lineare Regression und neuronale Netzwerke.
Was ist das beste Modell für maschinelles Lernen?
Zu den verschiedenen Modellen des maschinellen Lernens gehören Naive Bayes, KNN, Random Forest, Boosting, AdaBoot, Lineare Regression und mehr. Welches Modell Sie auswählen müssen, hängt jedoch von der Situation oder dem Projekt ab, an dem Sie arbeiten. Wir haben einige der oben genannten Beispiele und die besten zu verwendenden Modelle und Algorithmen erwähnt.
Was sind die 4 Modelle des maschinellen Lernens?
Die vier Modelle des maschinellen Lernens sind das überwachte Lernmodell, das unüberwachte Lernmodell, das halbüberwachte Lernmodell und das bestärkende Lernmodell. Jedes dieser Modelle hat seine eigenen Vorzüge, daher sollten sie alle zusammen verwendet werden.


Schreibe einen Kommentar