
Das neueste Patent von Microsoft generiert hyperreale virtuelle Avatare basierend auf den Gesichtern der Benutzer
Microsoft hat etwas Besonderes mit virtuellen Avataren: Die kürzlich veröffentlichte Mesh-Plattform ermöglicht es Teams-Benutzern, Avatare zu erstellen, um an sogenannten virtuellen Immersionsräumen teilzunehmen. Dabei handelt es sich um Kontexte, in denen Mitarbeiter virtuell zusammen abhängen können, auch wenn sie meilenweit voneinander entfernt sind.
Microsoft Mesh ist in der Tat eine unterhaltsame Plattform, und der in Redmond ansässige Technologieriese sagt, dass es funktioniert: Viele Microsoft-Mitarbeiter verspüren ein Gefühl der Verbundenheit, wenn sie dort abhängen. Aber gleichzeitig fühlt es sich komisch an: Die cartoonartigen Avatare sind zwar niedlich und alles, wirken aber deplatziert.
Es scheint jedoch, dass der in Redmond ansässige Technologieriese bereits an einem Update arbeitet. Das Unternehmen hat kürzlich ein Patent veröffentlicht, das eine Technologie beschreibt, mit der hyperreale virtuelle Avatare auf der Grundlage der Gesichter der Benutzer erstellt werden können.
Die Technologie trägt den Namen „ Multi-modal Three-Dimensional Face Modeling and Tracking for Generating Expressive Avatars“ und beschreibt ein Computersystem, das mittels 3D-Gesichtsmodellierung und -Tracking ausdrucksstarke Avatare erstellt.
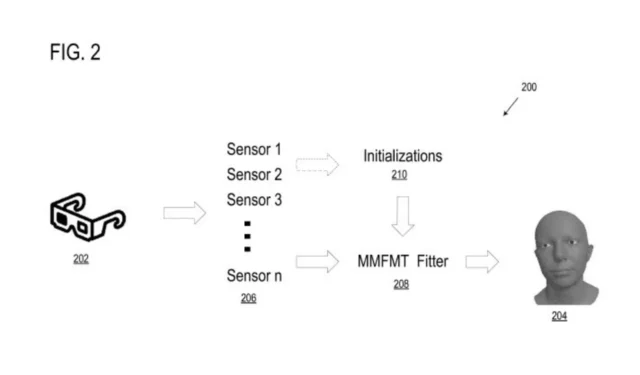
Das Computersystem verfügt über einen eigenen Prozessor und ein eigenes Speichersystem, das die zur Modellierung des hyperrealen virtuellen Avatars benötigten Daten verarbeitet und speichert. Es speichert auch Anweisungen zum Rendern der Daten.
Der Prozessor empfängt dann Initialisierungsdaten, also das Ausgangsaussehen eines Gesichtsmodells, und zusätzliche multimodale Datensignale, bei denen es sich um Audiodaten (wie etwa die Stimme des Benutzers) handeln kann, die zur Erstellung eines hyperrealistischen Gesichtsmodells verwendet werden.
Die Initialisierungs- und Multimodaldaten werden dann vom System übernommen und in einem Anpassungsprozess gemeinsam verarbeitet. Dieser Prozess passt die Daten an das Modell an. Basierend auf dem Anpassungsprozess bestimmt das System dann einen Satz von Parametern, die zur Beschreibung des hyperrealen virtuellen Avatars verwendet werden.
Das System verwendet Deep Learning, um einen detaillierten virtuellen Avatar zu erstellen, der ähnlich oder identisch mit dem Gesicht des Benutzers aussieht, handelt und Gesichtsausdrücke machen kann. Deep Learning ist eine Form der KI-Technologie, die das menschliche Gehirn so weit wie möglich nachahmt, und Microsoft hat in den letzten Jahren darin investiert.
Da es sich um ein Computersystem handelt, erwähnt das Dokument die Möglichkeit, es in eine Vielzahl von Geräten zu integrieren, von VR-/AR-/MR-Headsets bis hin zu Mobiltelefonen, Laptops, Spielekonsolen, Tablet-Computern und vielen mehr, was bedeutet, dass Benutzer über ein Gerät verfügen könnten, mit dem sie ihre virtuellen Avatare in einen Meta- oder Mesh-ähnlichen virtuellen Raum transportieren können.
Microsoft könnte versuchen, dieses neue hyperreale virtuelle Avatarsystem in bestehende Plattformen wie Microsoft Teams, Microsoft Mesh oder sogar Windows zu implementieren.
Obwohl es bereits virtuelle Räume gibt, erfreuen sie sich derzeit aufgrund ihrer begrenzten Möglichkeiten keiner großen Beliebtheit. Ein System wie dieses kann jedoch mehr Menschen dazu ermutigen, virtuellen Räumen beizutreten.
Auch die Gaming-Branche könnte von dieser Technologie profitieren, da sie es den Benutzern ermöglicht, ihre Charaktere anhand ihres Aussehens anzupassen und so ebenfalls für ein hochgradig personalisiertes Gaming-Erlebnis zu sorgen.
Den vollständigen Artikel können Sie hier lesen .
Das Framework verwendet Deep-Learning-Techniken und Vorwärtsmodellierung, um einen parametrischen Anpassungsprozess durchzuführen, der die multimodalen Datensignale in einen Parametersatz oder Ausdruckscode übersetzt, der zur Generierung eines ausdrucksstarken 3D-Gesichtsmodells verwendet werden kann.
Microsoft
Techniken zur 3D-Gesichtsmodellierung und -verfolgung erstellen 3D-Scheitelpunkte auf Grundlage des Gesichts eines Benutzers und wenden Transformationen auf die Scheitelpunkte eines neutralen Gesichts an, um Ausdrücke auf einem digitalen Gesichtsmodell darzustellen (z. B. eine Avatar-Darstellung des Gesichts des Benutzers).
Microsoft
Multimodale 3D-Gesichtsmodellierungs- und -verfolgungstechniken können mehrere verschiedene Sensorgeräte nutzen, von denen jedes ein oder mehrere Eingangssignale und/oder Messungen für das Gesicht eines Benutzers bereitstellt, um ein dreidimensionales Gesichtsmodell grafisch als Avatar zu erkennen, zu modellieren, zu verfolgen und/oder zu animieren.
Microsoft


Schreibe einen Kommentar