
KI dringt in Ihren Browser ein und das schneller als je zuvor
Wir haben uns gefragt, wann sie die volle Leistungsfähigkeit der KI in unseren Browsern nutzen werden, und offenbar ist die Zeit gekommen.
Wir sprechen von einer neuen Funktion namens ONNX Runtime Web, die den WebGPU-Beschleuniger nutzt, der es ermöglicht, KI-Modelle direkt in den Browser zu integrieren und sie schneller zu machen. Viel schneller!
Was ist das ONNX Runtime Web?
Um das zu erklären, müssen Sie wissen, dass WebGPU eine Engine ist, ähnlich wie WebGL, aber viel leistungsfähiger und in der Lage, größere Rechenlasten zu bewältigen. Im Grunde geht es darum, die GPU-Leistung zu nutzen, um parallele Rechenaufgaben auszuführen, die in KI-Prozessen erforderlich sind.
Kommen wir nun zu ONNX Runtime Web: Es handelt sich um eine JavaScript-Bibliothek, die es Webentwicklern ermöglicht, LLMs direkt in die Webbrowser einzubetten und von der GPU-Hardwarebeschleunigung zu profitieren.
Normalerweise lassen sich große LLMs nicht so einfach in Browsern bereitstellen, da sie viel Speicher und Rechenleistung benötigen.
Die Innovation von ONNX Runtime Web besteht darin, dass es das WebGPU-Backend ermöglicht, das Microsoft und Intel derzeit entwickeln.
Wie schnell ist das ONNX Runtime Web?
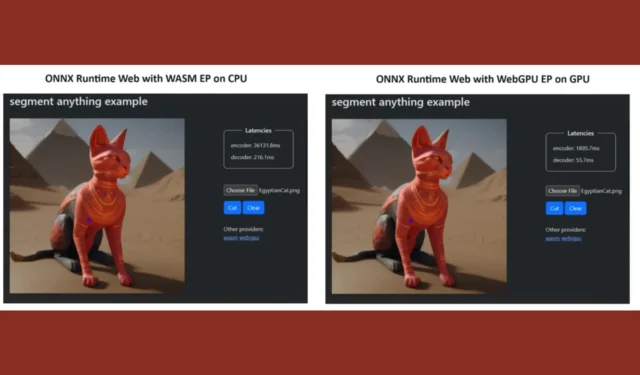
Um ihren Standpunkt zu beweisen, erstellte das ONNX Runtime-Team eine Demo mit dem Segment Anything-Modell und die Ergebnisse waren geradezu erstaunlich.
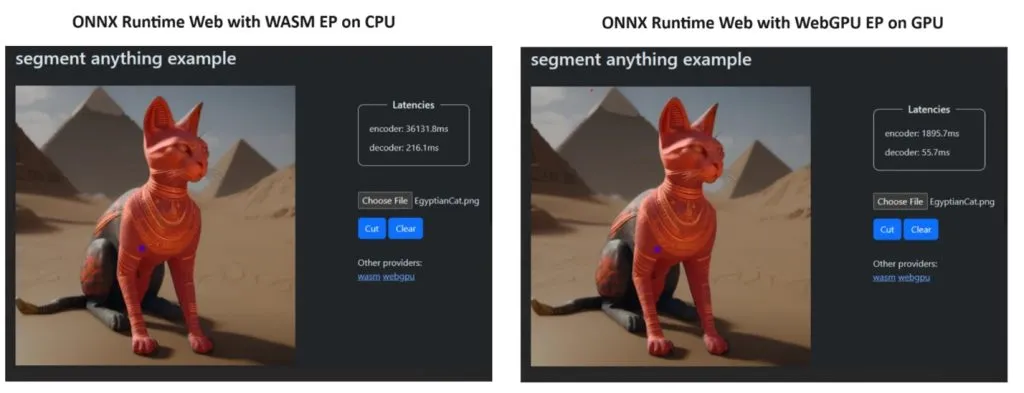
Sie integrierten WASM EP und WebGPU EP und verwendeten einen NVIDIA GeForce RTX 3060- und Intel Core i9-PC. Dann verglichen sie den Encoder mit der CPU und der neuen WebGPU und letztere erwies sich als viel schneller, wie im Screenshot oben gezeigt.
Die gute Nachricht ist, dass WebGPU bereits in Chrome 113 und Edge 113 für Windows, macOS und ChromeOS sowie Chrome 121 für Android eingebettet ist. Das bedeutet, dass Sie mit ONNX Runtime Web auch auf diesen Browsern spielen können.
Wie man ONNX Runtime Web ausprobiert, erklärten die Entwickler auf ihrer Projektseite:
Nachdem wir nun alles vorbereitet haben, beginnen wir mit der Bereitstellung einiger leistungsstarker LLMs in den Browsern!
Was denken Sie über das neue ONNX Runtime Web? Lassen Sie uns im Kommentarbereich unten über diese Entwicklung sprechen.
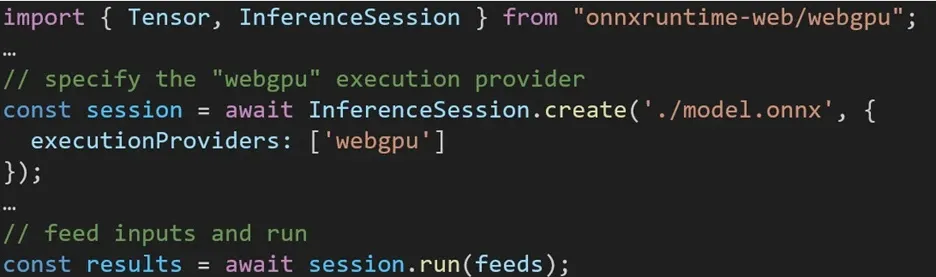
Die Nutzung verschiedener Backends in ONNX Runtime Web ist unkompliziert. Importieren Sie einfach das entsprechende Paket und erstellen Sie über die Einstellung „Ausführungsanbieter“ eine ONNX Runtime-Web-Inferenzsitzung mit dem erforderlichen Backend. Unser Ziel ist es, den Prozess für Entwickler zu vereinfachen, damit sie mit minimalem Aufwand unterschiedliche Hardwarebeschleunigungen nutzen können.
Der folgende Codeausschnitt zeigt, wie die ONNX Runtime Web API aufgerufen wird, um ein Modell mit WebGPU abzuleiten. Zusätzliche ONNX Runtime Web-Dokumentation und Beispiele stehen für tiefergehende Einblicke zur Verfügung.


Schreibe einen Kommentar