
知っておくべき最高の機械学習モデル
人工知能と機械学習の力を活用したいなら、最高の機械学習モデルのいくつかに精通している必要があります。機械学習モデルは数十種類あるため、プロジェクトに機械学習モデルを選択するときに少し混乱することがあります。この記事では、プロジェクトに応じて使用できる最高の機械学習モデルのいくつかについて説明します。
知っておくべき最高の機械学習モデル
次のプロジェクト、インスタンス、シナリオ用の機械学習モデルとアルゴリズムのリストがあります。
時系列予測のための機械学習モデル
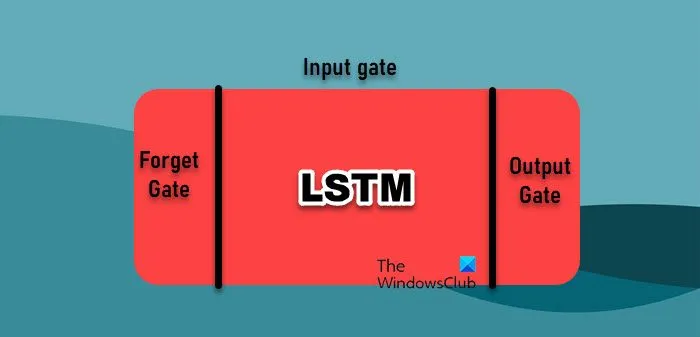
データ分析において、時系列予測は、それぞれに長所を持つさまざまな機械学習アルゴリズムに依存しています。しかし、ここでは最もよく使用される 2 つのアルゴリズムについて説明します。
- 長期短期記憶ネットワーク:長期短期記憶 (LSTM) ネットワークは、シーケンスからの学習に特に効果的なリカレント ニューラル ネットワーク (RNN) の一種で、時系列データに適しています。勾配消失問題により長期依存性に悩まされる従来の RNN とは異なり、LSTM は長期間にわたって情報を保持できます。これは、情報の流れを管理するゲートを含む独自のアーキテクチャによって実現され、時系列データの複雑なパターンをキャプチャできます。
- ランダム フォレスト:ランダム フォレストは、アンサンブル学習法 (ここでは 2 つ以上の学習者) です。トレーニング中に、複数の決定木を構築し、それらの予測を平均化します。これは元々時系列向けではありませんが、遅延変数を含めることで予測用に調整できます。ランダム フォレストは多くの機能を処理でき、過剰適合の可能性が低いため、複雑なデータセットに最適です。
これら 2 つのモデルと、VAR、ARIRA、Prophet モデルなどの他のいくつかのモデルを統合して、可能な限り最良の結果を得ることができます。
株価予測のための機械学習モデル

株価はランダムですが、同時にこのランダム性にもパターンがあります。プロジェクトで株価予測を行うことを目的とする場合は、以下に示すモデルのいずれかまたは両方を使用することをお勧めします。
- 決定木:決定木は、決定や予測を行うのに役立つフローチャートの一種です。決定木には、属性に対する決定やテストのためのノード、これらの決定の結果のためのブランチ、および最終的な結果や予測のためのリーフ ノードがあります。各内部ノードは属性に対するテストを表し、各ブランチはテストの結果を表し、各リーフ ノードはクラス ラベルまたは連続値を表します。
- ニューラル ネットワーク:ニューラル ネットワークは、人間の脳の複雑な機能を模倣したコンピュータ モデルです。相互接続されたノードまたはニューロンで構成され、データを処理し、データから学習します。これにより、機械学習におけるパターン認識や意思決定などのタスクが可能になります。適切にトレーニングすれば、株のマスターとして機能することができます。
ただし、株価パターンを把握するのは非常に難しい場合があることを覚えておく必要があります。そのため、これらのモデルに過度に依存せず、Randon Forest や LSTM などの他のモデルも取り入れるべきです。
多クラス分類のための機械学習モデル
さて、最も一般的な機械学習ジョブの 1 つであるマルチクラス分類について説明しましょう。ここでの私たちの仕事は、以前のデータを利用して、情報の一部を調べて分類できるモデルを作成することです。モデルはトレーニング データセットを分析して、各クラスの固有のパターンを見つけます。次に、これらのパターンを使用して将来のデータのカテゴリを予測します。最も一般的なアルゴリズムとモデルを 2 つ以下に示します。
- SVM は大量の情報を処理してパターンを見つけるのが得意なので、さまざまな分野で役立ちます。SVM が提供するこれらすべての機能により、データの監視と分類に使用できます。
- これには、多項式ナイーブベイズ、ベルヌーイ ナイーブベイズ、ガウス ナイーブベイズが含まれます。ナイーブベイズ分類器は、ベイズの定理に基づく分類アルゴリズムのグループです。これらは 1 つのアルゴリズムではなく、分類される特徴のすべてのペアが互いに独立しているという同じ原則に従うアルゴリズムのファミリーです。
この機能には、ニューラル ネットワーク (詳細は上記) を使用することもできます。
回帰のための機械学習モデル

回帰は、最も必要とされる特徴の 1 つである連続値を予測するために使用されます。そのため、ここではさまざまなアルゴリズムが使用されています。まずは、次の 2 つから始めることをお勧めします。
- 線形回帰:線形回帰は、機械学習で広く使用されているアルゴリズムです。データセットから主要な変数を選択して、将来の値などの出力変数を予測します。このアルゴリズムは、空港からの毎日のフライト数を予測するなど、連続ラベルを持つケースに適しています。線形回帰の表現は、y = ax + b です。
- リッジ回帰:リッジ回帰は、もう 1 つの一般的な ML アルゴリズムです。式 y = Xβ + ϵ を使用します。この場合、「y」は従属変数の観測値の N*1 ベクトルを表し、「X」は回帰子のマトリックスです。回帰係数は N*1 ベクトルである「β」で示され、「ϵ」はエラーのベクトルを表します。
ニューラル ネットワーク回帰、Lasso 回帰、ランダム フォレスト、決定木回帰、SVM、多項式回帰、ガウス回帰、KNN モデルなど、使用できる他の回帰手法もあります。
小規模データセット向けの機械学習モデル
小さなデータセットを扱う場合、使用できる ML モデルがいくつかあります。
- Elastic Net: Elastic Net は、Lasso (L1) 回帰法と Ridge (L2) 回帰法を組み合わせて、複数の相関特性を持つシナリオを処理する手法です。Lasso のスパース性と Ridge の正則化のバランスをとります。Elastic Net が小規模なデータセットに使用される理由は、相関性の高い予測子を処理する場合に適しているためです。また、L1 正則化と L2 正則化の両方を組み合わせるため、1 つの形式の正則化のみを使用するモデルと比較して、オーバーフィットをより効果的に防止できます。
- シングル ヒドゥン ニューラル ネットワーク:シングル ヒドゥン ニューラル ネットワークの場合、入力ニューラル ネットワーク層と出力ニューラル ネットワーク層は 1 つだけです。シンプルであるため、データの実装と理解が容易になります。これは、小規模なデータセットを扱うときに必要なことです。また、情報の一般化と解釈も容易になります。
小規模なデータセットには、線形判別分析、二次判別分析、一般化線型モデルなど、最も有用なさまざまなモデルを使用できます。
ビッグデータセット向け機械学習モデル
大規模なデータセット、つまりビッグ データを処理すると、貴重な洞察が得られる可能性が高まりますが、特有の課題も生じます。小規模データセットと大規模データセット向けのモデルを除き、これまでに説明したモデルのいずれかを使用できます。ただし、ここでの最大の問題は、このような大量のデータを処理することです。したがって、ここで説明するモデルとアルゴリズムは、膨大な量のデータを処理することを目的としています。
- バッチ処理:バッチ処理は、大規模なデータセットを小さなデータセット (バッチまたはパケット) に分割し、各バッチでモデルを段階的にトレーニングする手法です。この方法は、大規模なデータセットでよく発生する問題であるオーバーフィッティングを防ぎ、トレーニング プロセスをより管理しやすくします。
- 分散コンピューティング:分散コンピューティングとは、データとタスクを複数のマシンまたはプロセッサに分散して、大規模で複雑な機械学習モデルのトレーニングを高速化することを意味します。Apache Hadoop や Apache Spark などのフレームワークは、分散コンピューティングのための強力なプラットフォームを提供します。
大規模なデータセットには、線形回帰やニューラル ネットワークなどの他の ML モデルも使用できます。
最適な機械学習モデルは何ですか?
さまざまな機械学習モデルには、ナイーブベイズ、KNN、ランダムフォレスト、ブースティング、AdaBoot、線形回帰などがあります。ただし、選択する必要があるモデルは、状況や取り組んでいるプロジェクトによって異なります。上記では、いくつかの例と、使用するのに最適なモデルとアルゴリズムについて説明しました。
4 つの機械学習モデルとは何ですか?
機械学習モデルには、教師あり学習モデル、教師なし学習モデル、半教師あり学習モデル、強化学習モデルの 4 つがあります。それぞれに利点があるため、すべて一緒に使用する必要があります。


コメントを残す