
Reddit は Bing やその他の検索エンジンによるデータ取得をブロックしているが、Google はブロックしていない
知っておくべきこと
- Reddit は、Bing やその他の検索エンジンによるサイトのクロールを防ぐために robots.txt ファイルを更新しました。
- Redditは、この取り締まりは検索エンジンとの合意が破綻したことと、Redditのコンテンツの使用に関して強制力のある約束をすることを望まない企業によるものであると主張している。
- Google は、6,000 万ドルの契約のおかげで、検索結果に Reddit の最新コンテンツを表示できる唯一の大手検索エンジンです。
Reddit は、ウェブクローラーによるデータの使用を阻止する取り組みを強化している。この取り締まりの結果、現在、Bing や DuckDuckGo など、主要な検索エンジンはいずれも検索結果に Reddit の最近の投稿やコメントを表示できない。Google だけである。
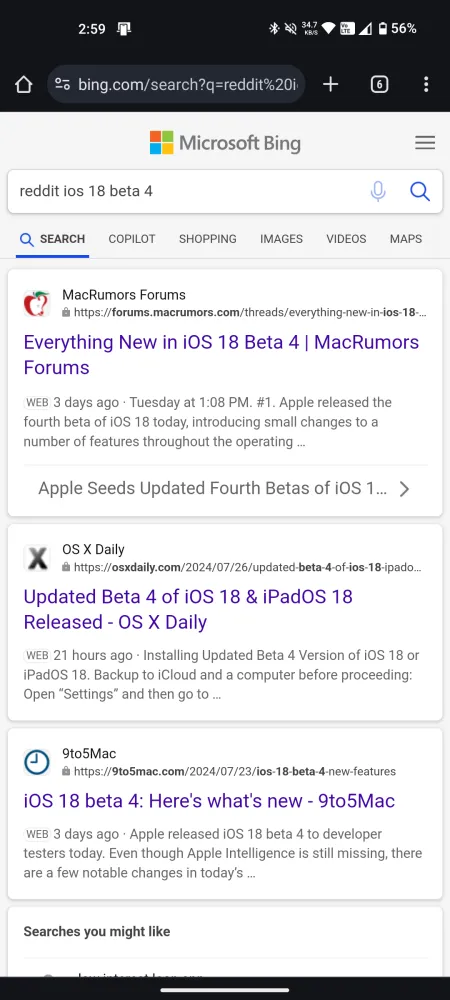
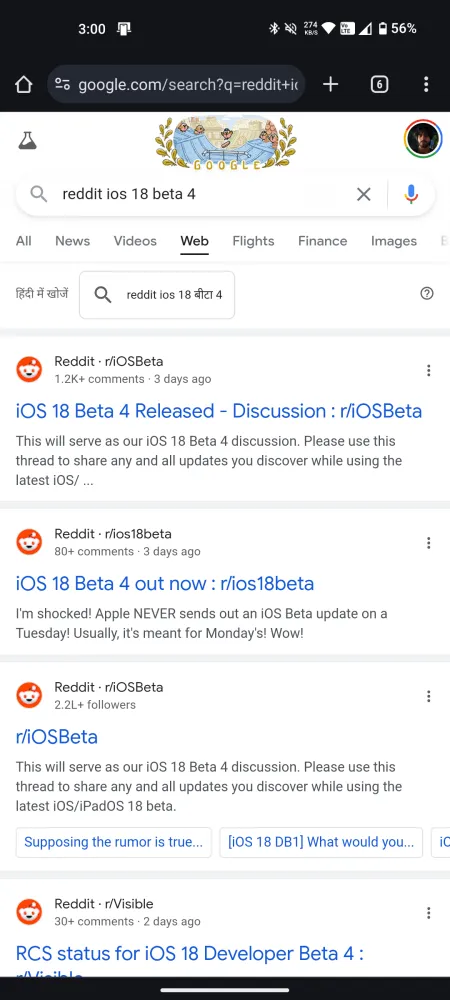
そのため、検索エンジンのクエリで最近の Reddit の結果を検索しようとしても、残念ながら何も見つかりません。最近のニュースの議論に関する同じクエリで、Bing と Google の検索結果を比較してみましょう。
Reddit は最近、ますますデータ保護を強化していますが、それは当然のことです。人々が集まって自分の興味について議論したり話したりする人気のコミュニティ フォーラムである Reddit は、AI トレーニングのまさに金鉱です。しかし、AI チャットボットが Web を席巻している時代に、Web サイトがいかに貴重なリソースであるかを、AI 企業と同様に Reddit も理解しています。
Reddit は、自社の利益を守るため、 Web クローラーが Web サイトにアクセスできないようにrobots.txt ファイルを更新しました。この動きは、Reddit のコンテンツの使用に関してさまざまな検索エンジンと合意に達する試みが何度も失敗した後に行われました。検索エンジンを取り締まり、データのスクレイピングを阻止することは、合意のない人は Reddit のコンテンツにアクセスすべきではないという明確なシグナルです。
現在、Google は Reddit の投稿やコメントを検索結果に表示できる唯一の大手検索エンジンです。そして、それは偶然ではありません。Reddit の広報担当者は声明で「これは Google との最近の提携とはまったく関係ありません」と述べていますが、Google が Reddit のデータで AI モデルをトレーニングすることを許可した 6,000 万ドルの契約を無視するのは簡単ではありません。この契約には Reddit のコンテンツへのリアルタイム アクセスも含まれていたようです。
Reddit からのメッセージは明らかです。支払わなければ、チャンスを逃すことになります。Microsoft を含むほとんどの企業が譲歩しました。Microsoft は声明で次のように述べています。
「当社は robots.txt 標準を尊重します。Bing は 7 月 1 日に更新された robots.txt ファイルを実装してサイトのすべてのクロールを禁止した後、Reddit のクロールを停止しました。」
Google 以外の検索エンジンを使用する人は明らかに不利な立場にあります。主な理由は、Reddit 自体の検索機能が、関連コンテンツの検索において検索エンジンほどうまく機能しないからです。現時点では、「site:reddit.com」というトリックを使用するか、クエリに「Reddit」という単語を追加して Reddit の最新の結果を取得したい場合は、まず Google を開く必要があります。


コメントを残す